
-
admin wrote a new post 2 weeks, 4 days ago
Google Introduces TurboQuant: A New Compression Algorithm that Reduces LLM Key-Value Cache Memory by 6x and Delivers Up to 8x Speedup, All with Zero Accuracy Loss
The scaling of Large Language Models (LLMs) is increasingly constrained by memory communication overhead between High-Bandwidth Memory (HBM) and SRAM. Specifically, the Key-Value (KV) cache size scales with both model dimensions and context length, creating a significant bottleneck for long-context inference. Google research team has proposed TurboQuant, a data-oblivious quantization framework designed to achieve near-optimal distortion rates for high-dimensional Euclidean vectors while addressing both mean-squared error (MSE) and inner product distortion. Addressing the Memory Wall with Data-Oblivious VQ Vector quantization (VQ) in Euclidean space is a foundational problem rooted in Shannon’s source coding theory. Traditional VQ algorithms, such as Product Quantization (PQ), often require extensive offline preprocessing and data-dependent codebook training, making them ill-suited for the dynamic requirements of real-time AI workloads like KV cache management. TurboQuant is a ‘data-oblivious’ algorithm and it does not require dataset-specific tuning or calibrations. It is designed to be highly compatible with modern accelerators like GPUs by leveraging vectorized operations rather than slow, non-parallelizable binary searches. The Geometric Mechanics of TurboQuant The core mechanism of TurboQuant involves applying a random rotation Π E Rdxd to the input vectors. This rotation induces a concentrated Beta distribution on each coordinate, regardless of the original input data. In high dimensions, these coordinates become nearly independent and identically distributed (i.i.d.). This near-independence simplifies the quantization design, allowing TurboQuant to solve a continuous 1D k-means / Max-Lloyd scalar quantization problem per coordinate. The optimal scalar quantizer for a given bit-width b is found by minimizing the following MSE cost function: $$mathcal{C}(f_{X},b):=min_{-1le c_{1}le c_{2}le…le c_{2^{b}}le1}sum_{i=1}^{2^{b}}int_{frac{c_{i-1}+c_{i}}{2}}^{frac{c_{i}+c_{i+1}}{2}}|x-c_{i}|^{2}cdot f_{X}(x)dx$$ By solving this optimization once for relevant bit-widths and storing the resulting codebooks, TurboQuant can efficiently quantize vectors during online inference. Eliminating Inner Product Bias A primary challenge in quantization is that maps optimized strictly for MSE often introduce bias when estimating inner products, which are the fundamental operations in transformer attention mechanisms. For example, a 1-bit MSE-optimal quantizer in high dimensions can exhibit a multiplicative bias of 2/π. To correct this, Google Research developed TURBOQUANTprod, a two-stage approach: MSE Stage: It applies a TURBOQUANTmse quantizer using a bit-width of b-1 to minimize the L2 norm of the residual vector. Unbiased Stage: It applies a 1-bit Quantized Johnson-Lindenstrauss (QJL) transform to the residual vector. This combination results in an overall bit-width of b while providing a provably unbiased estimator for inner products: (mathbb{E}_{Q}[langle y,Q^{-1}(Q(x))rangle ]=langle y,xrangle ) Theoretical and Empirical Performance The research team established information-theoretic lower bounds using Shannon’s Lower Bound (SLB) and Yao’s minimax principle. TurboQuant’s MSE distortion is provably within a small constant factor (≈ 2.7) of the absolute theoretical limit across all bit-widths. At a bit-width of b=1, it is only a factor of approximately 1.45 away from the optimal. Bit-width (b)TURBOQUANTmse DistortionInformation-Theoretic Lower Bound10.360.2520.1170.062530.030.015640.0090.0039 In end-to-end LLM generation benchmarks using Llama-3.1-8B-Instruct and Ministral-7B-Instruct, TurboQuant demonstrated high quality retention. Under a 4x compression ratio, the model maintained 100% retrieval accuracy on the Needle-In-A-Haystack benchmark. In the Needle-In-A-Haystack benchmark, TurboQuant matched full-precision performance up to 104k tokens under 4× compression. For non-integer bit-widths, the system employs an outlier treatment strategy, allocating higher precision (e.g., 3 bits) to specific outlier channels and lower precision (e.g., 2 bits) to non-outliers, resulting in effective bit-rates like 2.5 or 3.5 bits per channel. Speed and Indexing Efficiency In nearest neighbor search tasks, TurboQuant outperformed standard Product Quantization (PQ) and RabitQ in recall while reducing indexing time to virtually zero. Because TurboQuant is data-oblivious, it eliminates the need for the time-consuming k-means training phase required by PQ, which can take hundreds of seconds for large datasets. Approachd=200 Indexingd=1536 Indexingd=3072 IndexingProduct Quantization37.04s239.75s494.42sTurboQuant0.0007s0.0013s0.0021s TurboQuant represents a mathematically grounded shift toward efficient, hardware-compatible vector quantization that bridges the gap between theoretical distortion limits and practical AI deployment. Key Takeaways Zero Preprocessing Required: Unlike standard Product Quantization (PQ), TurboQuant is data-oblivious and it works instantly without needing time-consuming k-means training on your specific dataset. Near-Theoretical Perfection: It achieves near-optimal distortion rates, remaining within a small constant factor of approximately 2.7 of the information-theoretic lower bound established by Shannon. Unbiased Inner Products: By using a two-stage approach—applying MSE-optimal quantization followed by a 1-bit QJL transform on the residual—it provides unbiased inner product estimates, which is vital for maintaining the accuracy of transformer attention mechanisms. Massive Memory Savings: In LLM deployment, it compresses the KV cache by over 5x. It achieves absolute quality neutrality at 3.5 bits per channel and maintains 100% recall in ‘needle-in-a-haystack’ tests up to 104k tokens. Instant Indexing for Search: For vector databases, TurboQuant reduces indexing time to virtually zero (e.g., 0.0013s for 1536-dimensional vectors) while consistently outperforming traditional PQ in search recall. Check out the Paper and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Google Introduces TurboQuant: A New Compression Algorithm that Reduces LLM Key-Value Cache Memory by 6x and Delivers Up to 8x Speedup, All with Zero Accuracy Loss appeared first o […]
-
admin wrote a new post 2 weeks, 4 days ago
Viber Business Messaging: Your Ultimate Guide
 There are messaging apps, and then there are messaging apps… With over 1 billion users worldwide, V […]
There are messaging apps, and then there are messaging apps… With over 1 billion users worldwide, V […] -
admin wrote a new post 2 weeks, 4 days ago
AI Chatbot vs Live Chat for Cart RecoveryIn the fast-paced world of e-commerce in 2026, cart abandonment remains a persistent challenge, with […]
-
admin wrote a new post 2 weeks, 4 days ago
Agentic commerce runs on truth and contextImagine telling a digital agent, “Use my points and book a family trip to Italy. Keep it within b […]
-
admin wrote a new post 2 weeks, 4 days ago
The AI Hype Index: AI goes to war
AI is at war. Anthropic and the Pentagon feuded over how to weaponize Anthropic’s AI model Claude; then OpenAI s […]
-
admin wrote a new post 2 weeks, 5 days ago
TurboQuant: Redefining AI efficiency with extreme compressionAlgorithms & Theory
-
admin wrote a new post 2 weeks, 5 days ago
Mapping the modern world: How S2Vec learns the language of our citiesAlgorithms & Theory
-
admin wrote a new post 2 weeks, 5 days ago
Paged Attention in Large Language Models LLMs
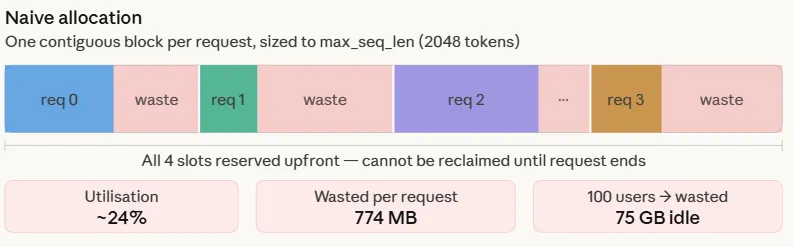 When running LLMs at scale, the real limitation is GPU memory rather than compute, mainly because […]
When running LLMs at scale, the real limitation is GPU memory rather than compute, mainly because […] -
admin wrote a new post 2 weeks, 5 days ago
-
admin wrote a new post 2 weeks, 5 days ago
The Best AI Chatbot Platforms for E-commerce in 2026In the fast-paced world of e-commerce, where customer expectations for instant support and […]
-
admin wrote a new post 2 weeks, 5 days ago
Exclusive eBook: Are we ready to hand AI agents the keys?We’re starting to give AI agents real autonomy, but are we prepared for what could h […]
-
admin wrote a new post 2 weeks, 5 days ago
This scientist rewarmed and studied pieces of his friend’s cryopreserved brainL. Stephen Coles’s brain sits cushioned in a vat at a storage f […]
-
admin wrote a new post 2 weeks, 5 days ago
Helping developers build safer AI experiences for teensOpenAI releases prompt-based teen safety policies for developers using gpt-oss-safeguard, helping moderate age-specific risks in AI systems.
-
admin wrote a new post 2 weeks, 5 days ago
Top 5 Free Google Certificate Courses in 2026For different learning goals and career paths, choosing the right certification can get confusing. […]
-
admin wrote a new post 2 weeks, 5 days ago
Mistral Small 4: The One Model That Codes, Reasons, and ChatsArtificial intelligence is rapidly evolving. New models emerge nearly every day, with […]
-
admin wrote a new post 2 weeks, 5 days ago
Yann LeCun’s New LeWorldModel (LeWM) Research Targets JEPA Collapse in Pixel-Based Predictive World Modeling
-
admin wrote a new post 2 weeks, 5 days ago
Meta AI’s New Hyperagents Don’t Just Solve Tasks—They Rewrite the Rules of How They Learn
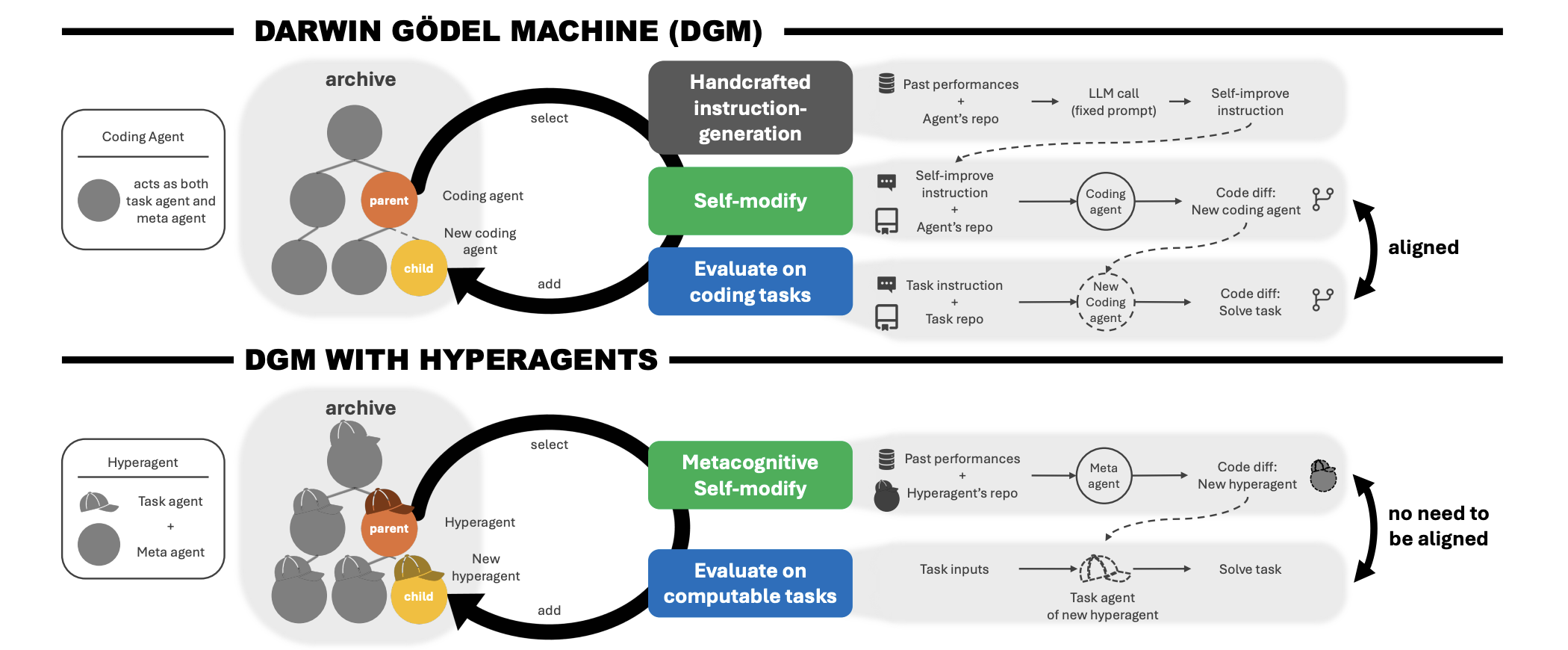 The dream of recursive self-improvement in AI—where a s […]
The dream of recursive self-improvement in AI—where a s […] -
admin wrote a new post 2 weeks, 5 days ago
AI Solutions for High-Volume Retail SupportIn 2026, AI chatbots are projected to handle up to 95% of customer interactions in retail, slashing […]
-
admin wrote a new post 2 weeks, 6 days ago
-
admin wrote a new post 2 weeks, 6 days ago
This is Hell: AI Actor Tilly Norwood’s “Take the Lead” Is a Crime Against MusicI don’t know who greenlit the idea of the Tilly Norwood music video “Take the Lead.” Still, whoever they are, they proved everyone right: AI creates…
- Load More
admin
Last active: Active 4 months ago
Comments: 0
Likes: 0
Submitted: 1307
Friends: 0
User Rating: Be the first one!


