
-
admin wrote a new post 1 week, 3 days ago
The Instagram Reels Algorithm, ExplainedWe’re giving you the secret sauce to crack the code on the Instagram Reels algorithm. Check out this guide for the insider tips.
-
admin wrote a new post 1 week, 3 days ago
The Download: plastic’s problem with fuel prices, and SpaceX’s blockbuster IPO
 This is today’s edition of The Download, our weekday newsletter that p […]
This is today’s edition of The Download, our weekday newsletter that p […] -
admin wrote a new post 1 week, 3 days ago
OpenAI acquires TBPNOpenAI acquires TBPN to accelerate global conversations around AI and support independent media, expanding dialogue with builders, businesses, and the broader tech community.
-
admin wrote a new post 1 week, 3 days ago
Claude Code Leak: 16 Lessons on Building Production-Ready AI SystemsOver the past 24 hours, the developer community has been obsessed with one […]
-
admin wrote a new post 1 week, 3 days ago
IBM Releases Granite 4.0 3B Vision: A New Vision Language Model for Enterprise Grade Document Data Extraction
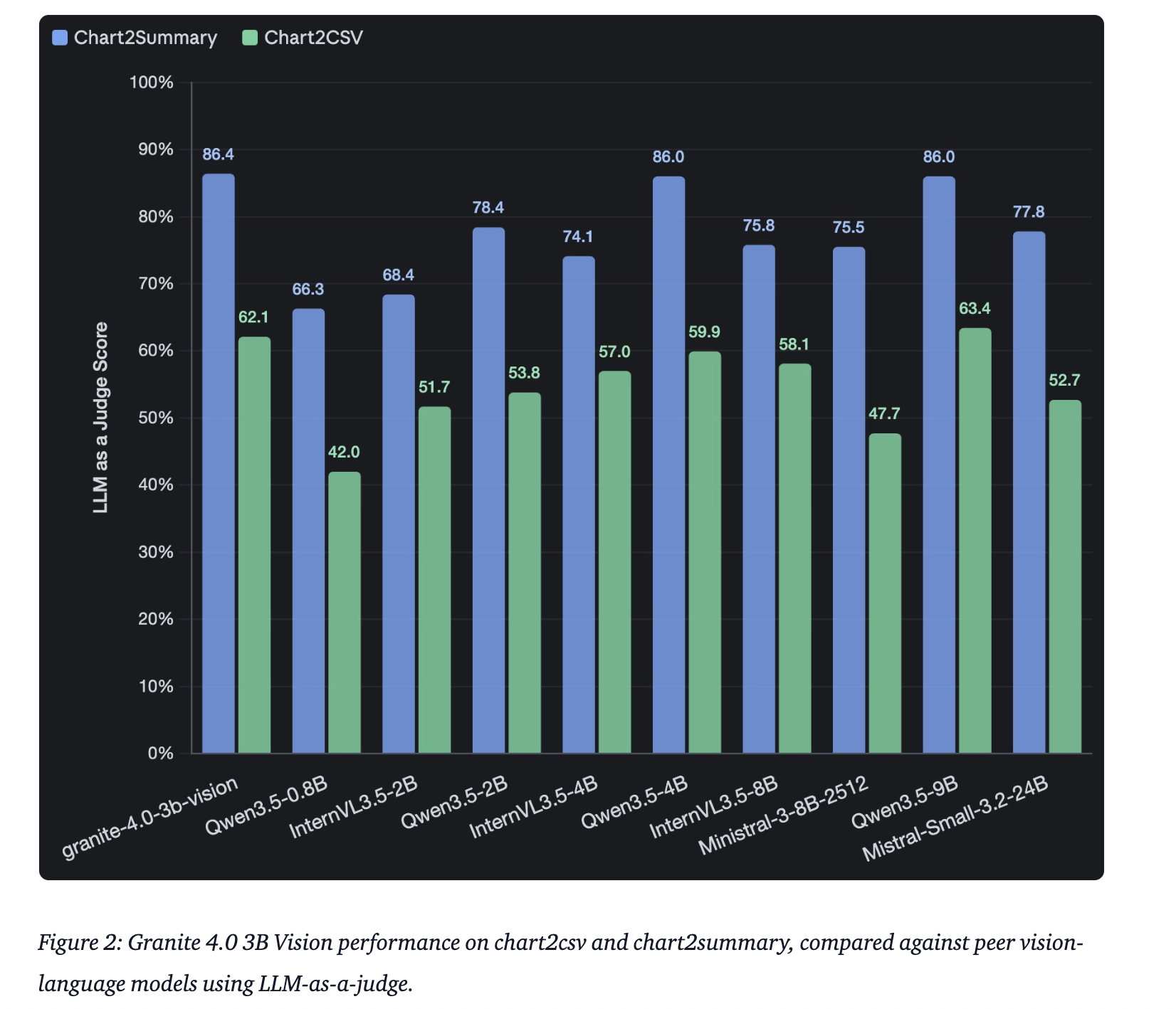 IBM has announced the release of […]
IBM has announced the release of […] -
admin wrote a new post 1 week, 3 days ago
-
admin wrote a new post 1 week, 3 days ago
Fuel prices are soaring. Plastic could be next.As the war in Iran continues to engulf the Middle East and the Strait of Hormuz stays closed, one of […]
-
admin wrote a new post 1 week, 4 days ago
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
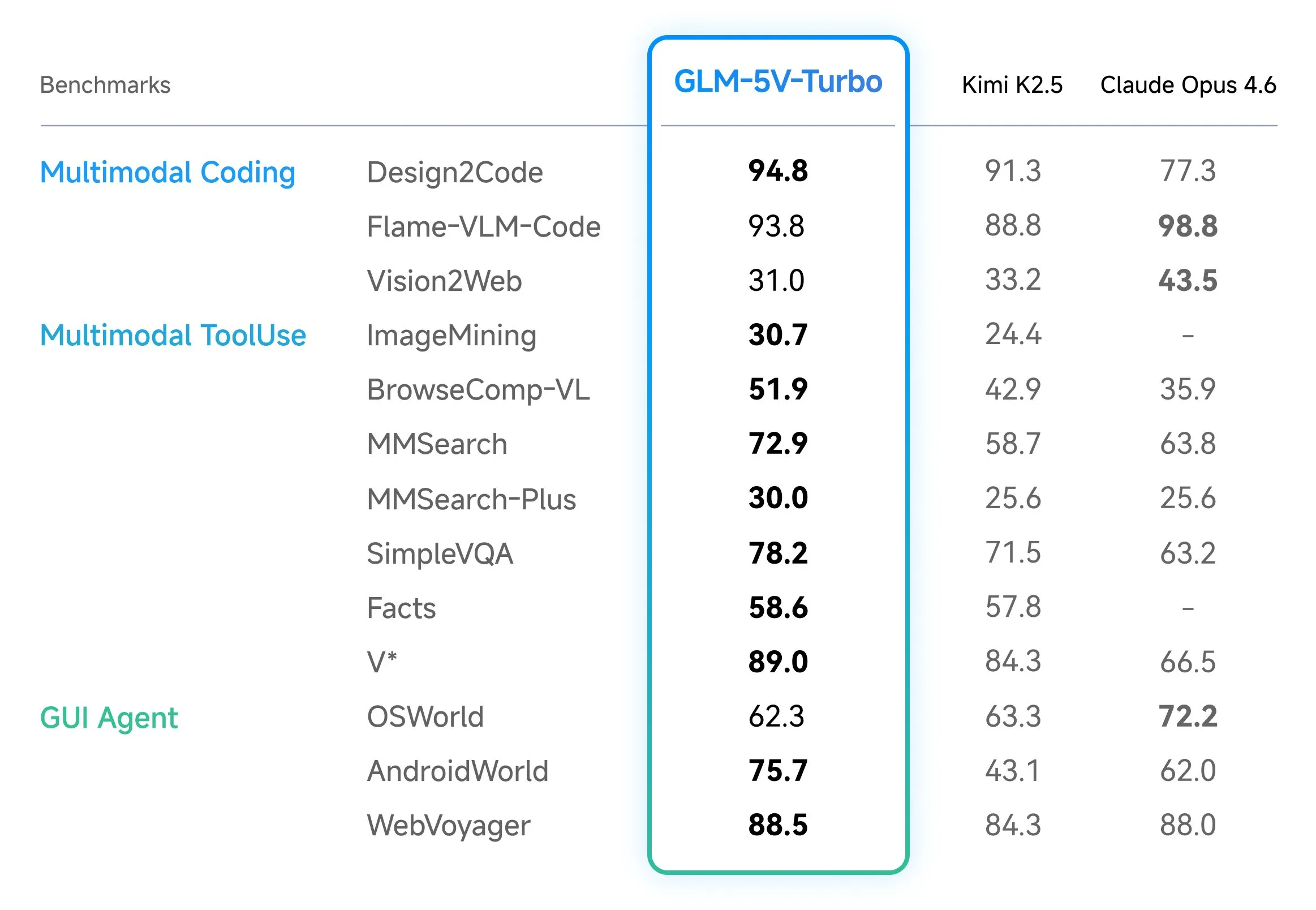 In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision coding model designed to address this specifically through Native Multimodal Coding and optimized training paths for agentic workflows. Documented Training and Design Choices: Native Multimodal Fusion A core technical distinction of GLM-5V-Turbo is its Native Multimodal Fusion. In many previous-generation systems, vision and language were treated as separate pipelines, where a vision encoder would generate a textual description for a language model to process. GLM-5V-Turbo utilizes a native approach, meaning it is designed to understand multimodal inputs—including images, videos, design drafts, and complex document layouts—as primary data during its training stages. The model’s performance is supported by two specific documented design choices: CogViT Vision Encoder: This component is responsible for processing visual inputs, ensuring that spatial hierarchies and fine-grained visual details are preserved. MTP (Multi-Token Prediction) Architecture: This choice is intended to improve inference efficiency and reasoning, which is critical when the model must output long sequences of code or navigate complex GUI environments. These choices allow the model to maintain a 200K context window, enabling it to process large amounts of data, such as extensive technical documentation or lengthy video recordings of software interactions, while supporting a high output capacity for code generation. 30+ Task Joint Reinforcement Learning One of the significant challenges in VLM development is the ‘see-saw’ effect, where improving a model’s visual recognition can lead to a decline in its programming logic. To mitigate this, GLM-5V-Turbo was developed using 30+ Task Joint Reinforcement Learning (RL). This training methodology involves optimizing the model across thirty distinct tasks simultaneously. These tasks span several domains essential for engineering: STEM Reasoning: Maintaining the logical and mathematical foundations required for programming. Visual Grounding: The ability to precisely identify the coordinates and properties of elements within a visual interface. Video Analysis: Interpreting temporal changes, which is necessary for debugging animations or understanding user flows in a recorded session. Tool Use: Enabling the model to interact with external software tools and APIs. By using joint RL, the model achieves a balance between visual and programming capabilities. This is particularly relevant for GUI Agents—AI systems that must “see” a graphical user interface and then generate the code or commands necessary to interact with it. Integration with OpenClaw and Claude Code The utility of GLM-5V-Turbo is highlighted by its optimization for specific agentic ecosystems. Rather than acting as a general-purpose AI, the model is built for Deep Adaptation within workflows involving OpenClaw and Claude Code. Optimized for OpenClaw Workflows OpenClaw is an open-source framework designed for building agents that operate within graphical user interfaces. GLM-5V-Turbo is integrated and optimized for OpenClaw workflows, serving as a foundation for tasks such as environment deployment, development, and analysis. In these scenarios, the model’s ability to process design drafts and document layouts is used to automate the setup and manipulation of software environments. Visually Grounded Coding with Claude Code The model also works with frameworks such as Claude Code for visually grounded coding workflows. This is especially useful in ‘Claw Scenarios,’ where a developer might need to provide a screenshot of a bug or a mockup of a new feature. Because GLM-5V-Turbo natively understands multimodal inputs, it can interpret the visual layout and provide code suggestions that are grounded in the visual evidence provided by the user. Benchmarks and Performance Validation The effectiveness of these design choices is measured through a suite of core benchmarks that focus on multimodal coding and tool use. For engineers evaluating the model, three documented benchmarks are central: BenchmarkTechnical FocusCC-Bench-V2Evaluates multimodal coding across backend, frontend, and repository-level tasks.ZClawBenchMeasures the model’s effectiveness in OpenClaw-specific agent scenarios.ClawEvalTests the model’s performance in multi-step execution and environment interaction. These metrics indicate that GLM-5V-Turbo maintains leading performance in tasks that require high-fidelity document layout understanding and the ability to navigate complex interfaces visually. Key Takeaways Native Multimodal Fusion: It natively understands images, videos, and document layouts via the CogViT vision encoder, enabling direct ‘Vision-to-Code’ execution without intermediate text descriptions. Agentic Optimization: The model is specifically integrated for OpenClaw and Claude Code workflows, mastering the ‘perceive → plan → execute’ loop for autonomous environment interaction. High-Throughput Architecture: It utilizes an inference-friendly MTP (Multi-Token Prediction) architecture, supporting a 200K context window and up to 128K output tokens for repository-scale tasks. Balanced Training: Through 30+ Task Joint Reinforcement Learning, it maintains rigorous programming logic and STEM reasoning while scaling its visual perception capabilities. Benchmarks: It delivers SOTA performance on specialized agentic leaderboards, including CC-Bench-V2 (coding/repo exploration) and ZClawBench (GUI agent interaction). Check out the Technical details and Try it here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on Ma […]
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision coding model designed to address this specifically through Native Multimodal Coding and optimized training paths for agentic workflows. Documented Training and Design Choices: Native Multimodal Fusion A core technical distinction of GLM-5V-Turbo is its Native Multimodal Fusion. In many previous-generation systems, vision and language were treated as separate pipelines, where a vision encoder would generate a textual description for a language model to process. GLM-5V-Turbo utilizes a native approach, meaning it is designed to understand multimodal inputs—including images, videos, design drafts, and complex document layouts—as primary data during its training stages. The model’s performance is supported by two specific documented design choices: CogViT Vision Encoder: This component is responsible for processing visual inputs, ensuring that spatial hierarchies and fine-grained visual details are preserved. MTP (Multi-Token Prediction) Architecture: This choice is intended to improve inference efficiency and reasoning, which is critical when the model must output long sequences of code or navigate complex GUI environments. These choices allow the model to maintain a 200K context window, enabling it to process large amounts of data, such as extensive technical documentation or lengthy video recordings of software interactions, while supporting a high output capacity for code generation. 30+ Task Joint Reinforcement Learning One of the significant challenges in VLM development is the ‘see-saw’ effect, where improving a model’s visual recognition can lead to a decline in its programming logic. To mitigate this, GLM-5V-Turbo was developed using 30+ Task Joint Reinforcement Learning (RL). This training methodology involves optimizing the model across thirty distinct tasks simultaneously. These tasks span several domains essential for engineering: STEM Reasoning: Maintaining the logical and mathematical foundations required for programming. Visual Grounding: The ability to precisely identify the coordinates and properties of elements within a visual interface. Video Analysis: Interpreting temporal changes, which is necessary for debugging animations or understanding user flows in a recorded session. Tool Use: Enabling the model to interact with external software tools and APIs. By using joint RL, the model achieves a balance between visual and programming capabilities. This is particularly relevant for GUI Agents—AI systems that must “see” a graphical user interface and then generate the code or commands necessary to interact with it. Integration with OpenClaw and Claude Code The utility of GLM-5V-Turbo is highlighted by its optimization for specific agentic ecosystems. Rather than acting as a general-purpose AI, the model is built for Deep Adaptation within workflows involving OpenClaw and Claude Code. Optimized for OpenClaw Workflows OpenClaw is an open-source framework designed for building agents that operate within graphical user interfaces. GLM-5V-Turbo is integrated and optimized for OpenClaw workflows, serving as a foundation for tasks such as environment deployment, development, and analysis. In these scenarios, the model’s ability to process design drafts and document layouts is used to automate the setup and manipulation of software environments. Visually Grounded Coding with Claude Code The model also works with frameworks such as Claude Code for visually grounded coding workflows. This is especially useful in ‘Claw Scenarios,’ where a developer might need to provide a screenshot of a bug or a mockup of a new feature. Because GLM-5V-Turbo natively understands multimodal inputs, it can interpret the visual layout and provide code suggestions that are grounded in the visual evidence provided by the user. Benchmarks and Performance Validation The effectiveness of these design choices is measured through a suite of core benchmarks that focus on multimodal coding and tool use. For engineers evaluating the model, three documented benchmarks are central: BenchmarkTechnical FocusCC-Bench-V2Evaluates multimodal coding across backend, frontend, and repository-level tasks.ZClawBenchMeasures the model’s effectiveness in OpenClaw-specific agent scenarios.ClawEvalTests the model’s performance in multi-step execution and environment interaction. These metrics indicate that GLM-5V-Turbo maintains leading performance in tasks that require high-fidelity document layout understanding and the ability to navigate complex interfaces visually. Key Takeaways Native Multimodal Fusion: It natively understands images, videos, and document layouts via the CogViT vision encoder, enabling direct ‘Vision-to-Code’ execution without intermediate text descriptions. Agentic Optimization: The model is specifically integrated for OpenClaw and Claude Code workflows, mastering the ‘perceive → plan → execute’ loop for autonomous environment interaction. High-Throughput Architecture: It utilizes an inference-friendly MTP (Multi-Token Prediction) architecture, supporting a 200K context window and up to 128K output tokens for repository-scale tasks. Balanced Training: Through 30+ Task Joint Reinforcement Learning, it maintains rigorous programming logic and STEM reasoning while scaling its visual perception capabilities. Benchmarks: It delivers SOTA performance on specialized agentic leaderboards, including CC-Bench-V2 (coding/repo exploration) and ZClawBench (GUI agent interaction). Check out the Technical details and Try it here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on Ma […] -
admin wrote a new post 1 week, 4 days ago
-
admin wrote a new post 1 week, 4 days ago
Instagram Grid Layouts We Love (And How to Make Your Grid Bingeable)This guide will help you understand the benefits of adhering to a grid layout, which types of layouts you should avoid, and show you seven different layout types with inspiring examples.
-
admin wrote a new post 1 week, 4 days ago
The Download: gig workers training humanoids, and better AI benchmarksThis is today’s edition of The Download, our weekday newsletter that p […]
-
admin wrote a new post 1 week, 4 days ago
Gradient Labs gives every bank customer an AI account managerGradient Labs uses GPT-4.1 and GPT-5.4 mini and nano to power AI agents that automate banking support workflows with low latency and high reliability.
-
admin wrote a new post 1 week, 4 days ago
Speculative Decoding: How LLMs Generate Text 3x FasterYou probably use Google on a daily basis, and nowadays, you might have noticed AI-powered […]
-
admin wrote a new post 1 week, 4 days ago
Hugging Face Releases TRL v1.0: A Unified Post-Training Stack for SFT, Reward Modeling, DPO, and GRPO WorkflowsHugging Face has officially released […]
-
admin wrote a new post 1 week, 4 days ago
Google AI Releases Veo 3.1 Lite: Giving Developers Low Cost High Speed Video Generation via The Gemini API
 Google has announced the release of Veo […]
Google has announced the release of Veo […] -
admin wrote a new post 1 week, 4 days ago
The gig workers who are training humanoid robots at home
When Zeus, a medical student living in a hilltop city in central Nigeria, returns to his […]
-
admin wrote a new post 1 week, 5 days ago
Qwen3.5-Omni is here! Scaling up to a Native Omni-modal AGIMultimodal AI has grown from novelty to a must in recent times. Need proof? If I were […]
-
admin wrote a new post 1 week, 5 days ago
Building better AI benchmarks: How many raters are enough?Algorithms & Theory
-
admin wrote a new post 1 week, 5 days ago
-
admin wrote a new post 1 week, 5 days ago
How to Change the Background on Your Instagram StoryThis quick guide will show you how to change the background of your Instagram Story using three different methods.
- Load More
admin
Last active: Active 4 months ago
Comments: 0
Likes: 0
Submitted: 1306
Friends: 0
User Rating: Be the first one!

