
-
admin wrote a new post 1 week, 1 day ago
How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory ConsolidationIn this tutorial, we build an EverMem-style persistent agent OS. We combine short-term conversational context (STM) with long-term vector memory using FAISS so the agent can recall relevant past information before generating each response. Alongside semantic memory, we also store structured records in SQLite to persist metadata like timestamps, importance scores, and memory signals (preference, fact, task, decision). As we interact with the agent, we see it form new memories, retrieve the most relevant ones for the current query, and maintain consistent behavior across turns. Copy CodeCopiedUse a different Browser!pip -q install -U transformers sentence-transformers faiss-cpu accelerate import os, time, json, math, sqlite3, hashlib from dataclasses import dataclass from typing import List, Dict, Any, Optional import numpy as np import faiss import torch from sentence_transformers import SentenceTransformer from transformers import AutoTokenizer, AutoModelForSeq2SeqLM def _now_ts(): return int(time.time()) def _sha(s: str) -> str: return hashlib.sha256(s.encode(“utf-8″, errors=”ignore”)).hexdigest()[:16] def _ensure_dir(p: str): os.makedirs(p, exist_ok=True) def _safe_clip(text: str, max_chars: int = 1800) -> str: text = (text or “”).strip() if len(text) np.ndarray: vecs = self.embedder.encode(texts, convert_to_numpy=True, normalize_embeddings=True) if vecs.ndim == 1: vecs = vecs.reshape(1, -1) return vecs.astype(“float32”) def _tokens_est(self, text: str) -> int: text = text or “” return max(1, int(len(text.split()) * 1.25)) def _importance_score(self, role: str, text: str, meta: Dict[str, Any]) -> float: base = 0.35 length_bonus = min(0.45, math.log1p(len(text)) / 20.0) role_bonus = 0.08 if role == “user” else 0.03 pin = 0.35 if meta.get(“pinned”) else 0.0 signal = meta.get(“signal”, “”) signal_bonus = 0.18 if signal in {“decision”, “preference”, “fact”, “task”} else 0.0 q_bonus = 0.06 if “?” in text else 0.0 number_bonus = 0.05 if any(ch.isdigit() for ch in text) else 0.0 return float(min(1.0, base + length_bonus + role_bonus + pin + signal_bonus + q_bonus + number_bonus)) def upsert_kv(self, k: str, v: Any): conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute( “INSERT INTO kv_store (k, v_json, updated_ts) VALUES (?, ?, ?) ON CONFLICT(k) DO UPDATE SET v_json=excluded.v_json, updated_ts=excluded.updated_ts”, (k, json.dumps(v, ensure_ascii=False), _now_ts()), ) conn.commit() conn.close() def get_kv(self, k: str, default=None): conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute(“SELECT v_json FROM kv_store WHERE k=?”, (k,)) row = cur.fetchone() conn.close() if not row: return default try: return json.loads(row[0]) except Exception: return default def add_memory(self, role: str, text: str, meta: Optional[Dict[str, Any]] = None) -> str: meta = meta or {} text = (text or “”).strip() mid = meta.get(“mid”) or f”m:{_sha(f'{_now_ts()}::{role}::{text[:80]}::{np.random.randint(0, 10**9)}’)}” created_ts = _now_ts() tokens_est = self._tokens_est(text) importance = float(meta.get(“importance”)) if meta.get(“importance”) is not None else self._importance_score(role, text, meta) conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute( “INSERT OR REPLACE INTO memories (mid, role, text, created_ts, importance, tokens_est, meta_json) VALUES (?, ?, ?, ?, ?, ?, ?)”, (mid, role, text, created_ts, importance, tokens_est, json.dumps(meta, ensure_ascii=False)), ) conn.commit() conn.close() vec = self._embed([text]) fid = self.next_faiss_id self.next_faiss_id += 1 self.index.add(vec) self.id_map[fid] = mid self._persist_faiss() return mid We initialize the EverMemAgentOS class and configure the embedding model, generation model, device selection, and memory hyperparameters. We create the SQLite schema for persistent storage and initialize the FAISS index for vector-based long-term memory retrieval. We also implement a memory-writing pipeline, including importance scoring and vector insertion, enabling the agent to store structured and semantic memory simultaneously. Copy CodeCopiedUse a different Browserdef _fetch_memories_by_ids(self, mids: List[str]) -> List[MemoryItem]: if not mids: return [] placeholders = “,”.join([“?”] * len(mids)) conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute( f”SELECT mid, role, text, created_ts, importance, tokens_est, meta_json FROM memories WHERE mid IN ({placeholders})”, mids, ) rows = cur.fetchall() conn.close() items = [] for r in rows: meta = {} try: meta = json.loads(r[6]) if r[6] else {} except Exception: meta = {} items.append( MemoryItem( mid=r[0], role=r[1], text=r[2], created_ts=int(r[3]), importance=float(r[4]), tokens_est=int(r[5]), meta=meta, ) ) mid_pos = {m: i for i, m in enumerate(mids)} items.sort(key=lambda x: mid_pos.get(x.mid, 10**9)) return items def retrieve_ltm(self, query: str, topk: Optional[int] = None) -> List[MemoryItem]: topk = topk or self.ltm_topk qv = self._embed([query]) scores, ids = self.index.search(qv, topk + 8) mids = [] for fid in ids[0].tolist(): if fid == -1: continue mid = self.id_map.get(int(fid)) if mid: mids.append(mid) mids = list(dict.fromkeys(mids))[:topk] return self._fetch_memories_by_ids(mids) def _format_stm(self) -> str: turns = self.stm[-self.stm_max_turns:] chunks = [] for t in turns: chunks.append(f”{t[‘role’].upper()}: {t[‘content’]}”) return “n”.join(chunks).strip() def _format_ltm(self, ltm_items: List[MemoryItem]) -> str: if not ltm_items: return “” lines = [] for i, it in enumerate(ltm_items, 1): ts_age = max(1, (_now_ts() – it.created_ts) // 3600) imp = f”{it.importance:.2f}” tag = it.meta.get(“signal”, “”) tag = f” | {tag}” if tag else “” lines.append(f”[LTM {i}] (imp={imp}, age_h={ts_age}{tag}) {it.role}: {_safe_clip(it.text, 420)}”) return “n”.join(lines).strip() @torch.inference_mode() def _gen(self, prompt: str, max_new_tokens: int = 180) -> str: inputs = self.tokenizer(prompt, return_tensors=”pt”, truncation=True, max_length=1024).to(self.device) out_ids = self.model.generate( **inputs, max_new_tokens=max_new_tokens, do_sample=True, temperature=0.6, top_p=0.92, num_beams=1, ) out = self.tokenizer.decode(out_ids[0], skip_special_tokens=True) return (out or “”).strip() def _compress_memories(self, items: List[MemoryItem], max_chars: int = 520) -> str: raw = “n”.join([f”- {it.role}: {it.text}” for it in items]) raw = _safe_clip(raw, 3500) prompt = ( “Summarize the following notes into a compact memory that preserves decisions, preferences, facts, and tasks. ” f”Keep it under {max_chars} characters.nnNOTES:n{raw}nnCOMPACT MEMORY:” ) summ = self._gen(prompt, max_new_tokens=170).strip() if len(summ) > max_chars: summ = summ[:max_chars].rstrip() + “…” return summ def consolidate(self) -> Optional[str]: conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute(“SELECT mid, role, text, created_ts, importance, tokens_est, meta_json FROM memories ORDER BY created_ts DESC LIMIT 160″) rows = cur.fetchall() conn.close() items = [] for r in rows: try: meta = json.loads(r[6]) if r[6] else {} except Exception: meta = {} items.append(MemoryItem(r[0], r[1], r[2], int(r[3]), float(r[4]), int(r[5]), meta)) if not items: return None items_sorted = sorted(items, key=lambda x: (-(x.importance + 0.15 * (1.0 / (1.0 + (_now_ts() – x.created_ts) / 3600.0))), -x.created_ts)) picked = items_sorted[:18] summary = self._compress_memories(picked, max_chars=520) cid = f”c:{_sha(f'{_now_ts()}::{summary[:120]}::{np.random.randint(0, 10**9)}’)}” source_mids = [it.mid for it in picked] conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute( “INSERT OR REPLACE INTO consolidations (cid, created_ts, summary, source_mids_json) VALUES (?, ?, ?, ?)”, (cid, _now_ts(), summary, json.dumps(source_mids, ensure_ascii=False)), ) conn.commit() conn.close() self.add_memory( role=”system”, text=f”Consolidated memory: {summary}”, meta={“signal”: “consolidation”, “pinned”: True, “source_mids”: source_mids, “cid”: cid, “importance”: 0.95}, ) return cid We implement semantic retrieval and formatting logic that enables the agent to fetch relevant long-term memories before reasoning. We define how short-term memory and retrieved long-term memory are structured and how they are injected into prompts for contextual generation. We also implement memory compression and consolidation logic, allowing the agent to periodically summarize high-value memories into durable long-term summaries. Copy CodeCopiedUse a different Browser def _should_consolidate(self) -> bool: if self.turns > 0 and self.turns % self.consolidate_every == 0: return True conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute(“SELECT SUM(tokens_est) FROM memories”) s = cur.fetchone()[0] conn.close() s = int(s or 0) return s >= self.consolidate_trigger_tokens def chat(self, user_text: str, user_meta: Optional[Dict[str, Any]] = None, max_answer_tokens: int = 220) -> Dict[str, Any]: user_meta = user_meta or {} self.turns += 1 self.stm.append({“role”: “user”, “content”: user_text}) self.stm = self.stm[-(self.stm_max_turns * 2):] self.add_memory(“user”, user_text, meta=user_meta) ltm = self.retrieve_ltm(user_text, topk=self.ltm_topk) stm_block = self._format_stm() ltm_block = self._format_ltm(ltm) sys_rules = ( “You are an AI agent with persistent memory. Use retrieved long-term memories to stay consistent. ” “If a memory conflicts with the user, ask a short clarifying question. Keep answers practical.” ) prompt = ( f”{sys_rules}nn” f”SHORT-TERM CONTEXT:n{_safe_clip(stm_block, 1800)}nn” f”RETRIEVED LONG-TERM MEMORIES:n{ltm_block if ltm_block else ‘(none)’}nn” f”USER REQUEST:n{user_text}nn” f”ANSWER:” ) answer = self._gen(prompt, max_new_tokens=max_answer_tokens) self.stm.append({“role”: “assistant”, “content”: answer}) self.stm = self.stm[-(self.stm_max_turns * 2):] self.add_memory(“assistant”, answer, meta={“signal”: “response”}) consolidation_id = None if self._should_consolidate(): consolidation_id = self.consolidate() return { “answer”: answer, “retrieved_ltm”: [ {“mid”: it.mid, “role”: it.role, “importance”: it.importance, “meta”: it.meta, “text”: _safe_clip(it.text, 320)} for it in ltm ], “consolidation_id”: consolidation_id, } def inspect_recent_memories(self, n: int = 12) -> List[Dict[str, Any]]: conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute(“SELECT mid, role, text, created_ts, importance, tokens_est, meta_json FROM memories ORDER BY created_ts DESC LIMIT ?”, (n,)) rows = cur.fetchall() conn.close() out = [] for r in rows: try: meta = json.loads(r[6]) if r[6] else {} except Exception: meta = {} out.append({“mid”: r[0], “role”: r[1], “created_ts”: int(r[3]), “importance”: float(r[4]), “tokens_est”: int(r[5]), “meta”: meta, “text”: _safe_clip(r[2], 520)}) return out def inspect_consolidations(self, n: int = 5) -> List[Dict[str, Any]]: conn = sqlite3.connect(self.db_path) cur = conn.cursor() cur.execute(“SELECT cid, created_ts, summary, source_mids_json FROM consolidations ORDER BY created_ts DESC LIMIT ?”, (n,)) rows = cur.fetchall() conn.close() out = [] for r in rows: try: src = json.loads(r[3]) if r[3] else [] except Exception: src = [] out.append({“cid”: r[0], “created_ts”: int(r[1]), “summary”: r[2], “source_mids”: src}) return out We implement the agent’s main reasoning loop in the chat() function, combining STM, LTM retrieval, and generation into a single workflow. We ensure that every interaction updates both vector memory and structured memory while maintaining contextual coherence. We also include automatic consolidation triggers so the system behaves like a persistent memory OS rather than a simple chatbot. Copy CodeCopiedUse a different Browseragent = EverMemAgentOS() agent.upsert_kv(“profile”, {“name”: “User”, “preferences”: {“style”: “concise”}}) demo_queries = [ (“I prefer answers in bullet points and I’m working on a Colab tutorial.”, {“signal”: “preference”, “pinned”: True}), (“Remember that my project is about an EverMem-style agent OS with FAISS + SQLite.”, {“signal”: “fact”, “pinned”: True}), (“Give me a 5-step plan to add memory importance scoring and consolidation.”, {“signal”: “task”}), (“Now remind me what you know about my preferences and project, briefly.”, {“signal”: “task”}), ] for q, meta in demo_queries: r = agent.chat(q, user_meta=meta, max_answer_tokens=180) print(“nUSER:”, q) print(“ASSISTANT:”, r[“answer”]) if r[“retrieved_ltm”]: print(“RETRIEVED_LTM:”, [(x[“importance”], x[“text”]) for x in r[“retrieved_ltm”][:3]]) if r[“consolidation_id”]: print(“CONSOLIDATED:”, r[“consolidation_id”]) print(“nRECENT MEMORIES:”) for m in agent.inspect_recent_memories(10): print(m[“role”], m[“importance”], m[“text”]) print(“nRECENT CONSOLIDATIONS:”) for c in agent.inspect_consolidations(3): print(c[“cid”], c[“summary”]) We instantiate the agent and simulate multi-turn interactions to demonstrate persistent recall and memory usage. We observe how the agent retrieves relevant long-term memories and uses them to produce consistent responses. Finally, we inspect stored memories and consolidations to verify that our EverMem-style architecture actively manages and evolves its memory over time. In conclusion, we have a working memory-centric agent that behaves less like a stateless chatbot and more like a persistent assistant that learns from interactions. We implemented importance scoring to prioritize what matters, vector retrieval to fetch the right context at the right time, and periodic consolidation to compress multiple memories into durable summaries that improve long-horizon recall. We also kept the system practical for Colab by using lightweight models, FAISS for fast similarity search, and SQLite for structured persistence. Check out the Full Codes here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory Consolidation appeared first on MarkTec […]
-
admin wrote a new post 1 week, 1 day ago
-
admin wrote a new post 1 week, 1 day ago
Which Type of Influencer Are You?Some influencers make a steady income off a few thousand followers; others have millions of followers but little engagement. And then some people go viral once,…
-
admin wrote a new post 1 week, 1 day ago
Bridging the operational AI gap
 The transformational potential of AI is already well established. Enterprise use cases are building momentum and […]
The transformational potential of AI is already well established. Enterprise use cases are building momentum and […] -
admin wrote a new post 1 week, 1 day ago
The Download: Earth’s rumblings, and AI for strikes on Iran
 This is today’s edition of The Download, our weekday newsletter that provides a daily d […]
This is today’s edition of The Download, our weekday newsletter that provides a daily d […] -
admin wrote a new post 1 week, 2 days ago
Extending single-minus amplitudes to gravitonsA new preprint extends single-minus amplitudes to gravitons, with GPT-5.2 Pro helping derive and verify nonzero graviton tree amplitudes in quantum gravity.
-
admin wrote a new post 1 week, 2 days ago
-
admin wrote a new post 1 week, 2 days ago
Introduction to Small Language Models: The Complete Guide for 2026 AI deployment is changing.
-
admin wrote a new post 1 week, 2 days ago
Beyond Accuracy: 5 Metrics That Actually Matter for AI AgentsAI agents , or autonomous systems powered by agentic AI, have reshaped the current landscape of AI systems and deployments.
-
admin wrote a new post 1 week, 2 days ago
OpenClaw vs Claude Code: Which AI Coding Agent Should You Use in 2026? AI coding agents are evolving fast. In 2026, OpenClaw and Claude Code […]
-
admin wrote a new post 1 week, 2 days ago
Meet SymTorch: A PyTorch Library that Translates Deep Learning Models into Human-Readable Equations
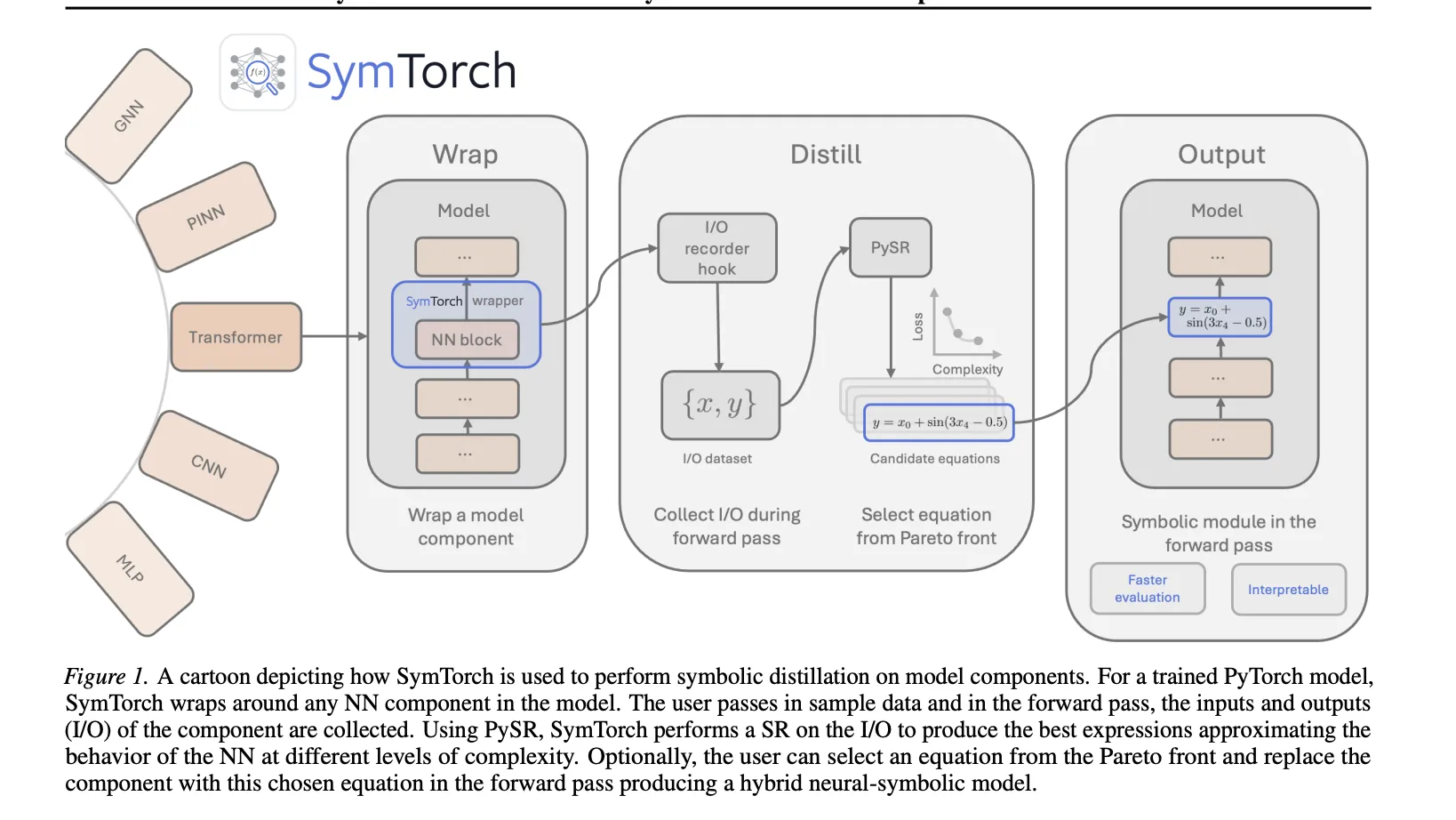 Can symbolic regression be the key to […]
Can symbolic regression be the key to […] -
admin wrote a new post 1 week, 2 days ago
How to Build a Stable and Efficient QLoRA Fine-Tuning Pipeline Using Unsloth for Large Language ModelsIn this tutorial, we demonstrate how to […]
-
admin wrote a new post 1 week, 2 days ago
-
admin wrote a new post 1 week, 2 days ago
The Download: The startup that says it can stop lightning, and inside OpenAI’s Pentagon deal
 This is today’s edition of The Download, our weekday n […]
This is today’s edition of The Download, our weekday n […] -
admin wrote a new post 1 week, 3 days ago
-
admin wrote a new post 1 week, 3 days ago
20 OpenClaw Prompts to Automate Your Daily Life and WorkAutonomous AI agents are easily among the most efficient uses of AI to date. And once you […]
-
admin wrote a new post 1 week, 3 days ago
-
admin wrote a new post 1 week, 3 days ago
-
admin wrote a new post 1 week, 3 days ago
This startup claims it can stop lightning and prevent catastrophic wildfiresOn June 1, 2023, as a sweltering heat wave baked Quebec, thousands of […]
-
admin wrote a new post 1 week, 3 days ago
10 Best YouTube Channels to Learn Generative AIGenerative AI is reshaping how software is built, content is created, and businesses operate. More […]
- Load More
admin
Last active: Active 3 months ago
SHARE:
Comments: 0
Likes: 0
Submitted: 1041
Friends: 0
User Rating: Be the first one!

Adsterra
🔥 Top Offers (Limited Time)
