
-
admin wrote a new post 2 months, 1 week ago
Knowledge Base Chatbots: Definition, Benefits & How to Build in 2026
 Imagine a world where your customers never have to wait for assistance from a […]
Imagine a world where your customers never have to wait for assistance from a […] -
admin wrote a new post 2 months, 2 weeks ago
Student ID Benefits Worth Thousands: Get 15+ Premium Tools For Free or on DiscountI remember from my student days the plethora of subscriptions, […]
-
admin wrote a new post 2 months, 2 weeks ago
15 Best Python Books for Beginners to Advanced Learners [2026 Edition]There is no shortage of resources available online and offline when it comes […]
-
admin wrote a new post 2 months, 2 weeks ago
Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching
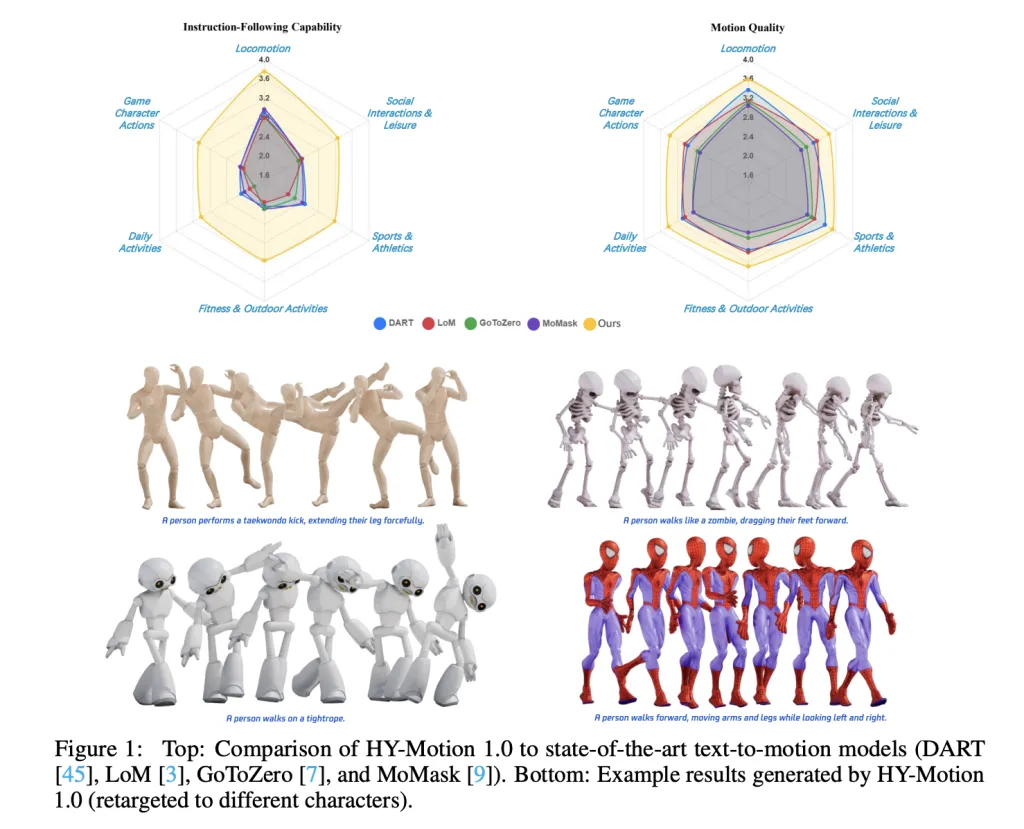 Tencent Hunyuan’s 3D Digital Human team has released HY-Motion 1.0, an open weight text-to-3D human motion generation family that scales Diffusion Transformer based Flow Matching to 1B parameters in the motion domain. The models turn natural language prompts plus an expected duration into 3D human motion clips on a unified SMPL-H skeleton and are available on GitHub and Hugging Face with code, checkpoints and a Gradio interface for local use. What HY-Motion 1.0 provides for developers? HY-Motion 1.0 is a series of text-to-3D human motion generation models built on a Diffusion Transformer, DiT, trained with a Flow Matching objective. The model series showcases 2 variants, HY-Motion-1.0 with 1.0B parameters as the standard model and HY-Motion-1.0-Lite with 0.46B parameters as a lightweight option. Both models generate skeleton based 3D character animations from simple text prompts. The output is a motion sequence on an SMPL-H skeleton that can be integrated into 3D animation or game pipelines, for example for digital humans, cinematics and interactive characters. The release includes inference scripts, a batch oriented CLI and a Gradio web app, and supports macOS, Windows and Linux. Data engine and taxonomy The training data comes from 3 sources, in the wild human motion videos, motion capture data and 3D animation assets for game production. The research team starts from 12M high quality video clips from HunyuanVideo, runs shot boundary detection to split scenes and a human detector to keep clips with people, then applies the GVHMR algorithm to reconstruct SMPL X motion tracks. Motion capture sessions and 3D animation libraries contribute about 500 hours of additional motion sequences. All data is retargeted onto a unified SMPL-H skeleton through mesh fitting and retargeting tools. A multi stage filter removes duplicate clips, abnormal poses, outliers in joint velocity, anomalous displacements, long static segments and artifacts such as foot sliding. Motions are then canonicalized, resampled to 30 fps and segmented into clips shorter than 12 seconds with a fixed world frame, Y axis up and the character facing the positive Z axis. The final corpus contains over 3,000 hours of motion, of which 400 hours are high quality 3D motion with verified captions. On top of this, the research team defines a 3 level taxonomy. At the top level there are 6 classes, Locomotion, Sports and Athletics, Fitness and Outdoor Activities, Daily Activities, Social Interactions and Leisure and Game Character Actions. These expand into more than 200 fine grained motion categories at the leaves, which cover both simple atomic actions and concurrent or sequential motion combinations. Motion representation and HY-Motion DiT HY-Motion 1.0 uses the SMPL-H skeleton with 22 body joints without hands. Each frame is a 201 dimensional vector that concatenates global root translation in 3D space, global body orientation in a continuous 6D rotation representation, 21 local joint rotations in 6D form and 22 local joint positions in 3D coordinates. Velocities and foot contact labels are removed because they slowed training and did not help final quality. This representation is compatible with animation workflows and close to the DART model representation. The core network is a hybrid HY Motion DiT. It first applies dual stream blocks that process motion latents and text tokens separately. In these blocks, each modality has its own QKV projections and MLP, and a joint attention module allows motion tokens to query semantic features from text tokens while keeping modality specific structure. The network then switches to single stream blocks that concatenate motion and text tokens into one sequence and process them with parallel spatial and channel attention modules to perform deeper multimodal fusion. For text conditioning, the system uses a dual encoder scheme. Qwen3 8B provides token level embeddings, while a CLIP-L model provides global text features. A Bidirectional Token Refiner fixes the causal attention bias of the LLM for non autoregressive generation. These signals feed the DiT through adaptive layer normalization conditioning. Attention is asymmetric, motion tokens can attend to all text tokens, but text tokens do not attend back to motion, which prevents noisy motion states from corrupting the language representation. Temporal attention inside the motion branch uses a narrow sliding window of 121 frames, which focuses capacity on local kinematics while keeping cost manageable for long clips. Full Rotary Position Embedding is applied after concatenating text and motion tokens to encode relative positions across the whole sequence. Flow Matching, prompt rewriting and training HY-Motion 1.0 uses Flow Matching instead of standard denoising diffusion. The model learns a velocity field along a continuous path that interpolates between Gaussian noise and real motion data. During training, the objective is a mean squared error between predicted and ground truth velocities along this path. During inference, the learned ordinary differential equation is integrated from noise to a clean trajectory, which gives stable training for long sequences and fits the DiT architecture. A separate Duration Prediction and Prompt Rewrite module improves instruction following. It uses Qwen3 30B A3B as the base model and is trained on synthetic user style prompts generated from motion captions with a VLM and LLM pipeline, for example Gemini 2.5 Pro. This module predicts a suitable motion duration and rewrites informal prompts into normalized text that is easier for the DiT to follow. It is trained first with supervised fine tuning and then refined with Group Relative Policy Optimization, using Qwen3 235B A22B as a reward model that scores semantic consistency and duration plausibility. Training follows a 3 stage curriculum. Stage 1 performs large scale pretraining on the full 3,000 hour dataset to learn a broad motion prior and basic text motion alignment. Stage 2 fine tunes on the 400 hour high quality set to sharpen motion detail and improve semantic correctness with a smaller learning rate. Stage 3 applies reinforcement learning, first Direct Preference Optimization using 9,228 curated human preference pairs sampled from about 40,000 generated pairs, then Flow GRPO with a composite reward. The reward combines a semantic score from a Text Motion Retrieval model and a physics score that penalizes artifacts like foot sliding and root drift, under a KL regularization term to stay close to the supervised model. Benchmarks, scaling behavior and limitations For evaluation, the team builds a test set of over 2,000 prompts that span the 6 taxonomy categories and include simple, concurrent and sequential actions. Human raters score instruction following and motion quality on a scale from 1 to 5. HY-Motion 1.0 reaches an average instruction following score of 3.24 and an SSAE score of 78.6 percent. Baseline text-to-motion systems such as DART, LoM, GoToZero and MoMask achieve scores between 2.17 and 2.31 with SSAE between 42.7 percent and 58.0 percent. For motion quality, HY-Motion 1.0 reaches 3.43 on average versus 3.11 for the best baseline. Scaling experiments study DiT models with 0.05B, 0.46B, 0.46B trained only on 400 hours and 1B parameters. Instruction following improves steadily with model size, with the 1B model reaching an average of 3.34. Motion quality saturates around the 0.46B scale, where the 0.46B and 1B models reach similar averages between 3.26 and 3.34. Comparison of the 0.46B model trained on 3,000 hours and the 0.46B model trained only on 400 hours shows that larger data volume is key for instruction alignment, while high quality curation mainly improves realism. Key Takeaways Billion scale DiT Flow Matching for motion: HY-Motion 1.0 is the first Diffusion Transformer based Flow Matching model scaled to the 1B parameter level specifically for text to 3D human motion, targeting high fidelity instruction following across diverse actions. Large scale, curated motion corpus: The model is pretrained on over 3,000 hours of reconstructed, mocap and animation motion data and fine tuned on a 400 hour high quality subset, all retargeted to a unified SMPL H skeleton and organized into more than 200 motion categories. Hybrid DiT architecture with strong text conditioning: HY-Motion 1.0 uses a hybrid dual stream and single stream DiT with asymmetric attention, narrow band temporal attention and dual text encoders, Qwen3 8B and CLIP L, to fuse token level and global semantics into motion trajectories. RL aligned prompt rewrite and training pipeline: A dedicated Qwen3 30B based module predicts motion duration and rewrites user prompts, and the DiT is further aligned with Direct Preference Optimization and Flow GRPO using semantic and physics rewards, which improves realism and instruction following beyond supervised training. Check out the Paper and Full Codes here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching appeared first on MarkTechP […]
Tencent Hunyuan’s 3D Digital Human team has released HY-Motion 1.0, an open weight text-to-3D human motion generation family that scales Diffusion Transformer based Flow Matching to 1B parameters in the motion domain. The models turn natural language prompts plus an expected duration into 3D human motion clips on a unified SMPL-H skeleton and are available on GitHub and Hugging Face with code, checkpoints and a Gradio interface for local use. What HY-Motion 1.0 provides for developers? HY-Motion 1.0 is a series of text-to-3D human motion generation models built on a Diffusion Transformer, DiT, trained with a Flow Matching objective. The model series showcases 2 variants, HY-Motion-1.0 with 1.0B parameters as the standard model and HY-Motion-1.0-Lite with 0.46B parameters as a lightweight option. Both models generate skeleton based 3D character animations from simple text prompts. The output is a motion sequence on an SMPL-H skeleton that can be integrated into 3D animation or game pipelines, for example for digital humans, cinematics and interactive characters. The release includes inference scripts, a batch oriented CLI and a Gradio web app, and supports macOS, Windows and Linux. Data engine and taxonomy The training data comes from 3 sources, in the wild human motion videos, motion capture data and 3D animation assets for game production. The research team starts from 12M high quality video clips from HunyuanVideo, runs shot boundary detection to split scenes and a human detector to keep clips with people, then applies the GVHMR algorithm to reconstruct SMPL X motion tracks. Motion capture sessions and 3D animation libraries contribute about 500 hours of additional motion sequences. All data is retargeted onto a unified SMPL-H skeleton through mesh fitting and retargeting tools. A multi stage filter removes duplicate clips, abnormal poses, outliers in joint velocity, anomalous displacements, long static segments and artifacts such as foot sliding. Motions are then canonicalized, resampled to 30 fps and segmented into clips shorter than 12 seconds with a fixed world frame, Y axis up and the character facing the positive Z axis. The final corpus contains over 3,000 hours of motion, of which 400 hours are high quality 3D motion with verified captions. On top of this, the research team defines a 3 level taxonomy. At the top level there are 6 classes, Locomotion, Sports and Athletics, Fitness and Outdoor Activities, Daily Activities, Social Interactions and Leisure and Game Character Actions. These expand into more than 200 fine grained motion categories at the leaves, which cover both simple atomic actions and concurrent or sequential motion combinations. Motion representation and HY-Motion DiT HY-Motion 1.0 uses the SMPL-H skeleton with 22 body joints without hands. Each frame is a 201 dimensional vector that concatenates global root translation in 3D space, global body orientation in a continuous 6D rotation representation, 21 local joint rotations in 6D form and 22 local joint positions in 3D coordinates. Velocities and foot contact labels are removed because they slowed training and did not help final quality. This representation is compatible with animation workflows and close to the DART model representation. The core network is a hybrid HY Motion DiT. It first applies dual stream blocks that process motion latents and text tokens separately. In these blocks, each modality has its own QKV projections and MLP, and a joint attention module allows motion tokens to query semantic features from text tokens while keeping modality specific structure. The network then switches to single stream blocks that concatenate motion and text tokens into one sequence and process them with parallel spatial and channel attention modules to perform deeper multimodal fusion. For text conditioning, the system uses a dual encoder scheme. Qwen3 8B provides token level embeddings, while a CLIP-L model provides global text features. A Bidirectional Token Refiner fixes the causal attention bias of the LLM for non autoregressive generation. These signals feed the DiT through adaptive layer normalization conditioning. Attention is asymmetric, motion tokens can attend to all text tokens, but text tokens do not attend back to motion, which prevents noisy motion states from corrupting the language representation. Temporal attention inside the motion branch uses a narrow sliding window of 121 frames, which focuses capacity on local kinematics while keeping cost manageable for long clips. Full Rotary Position Embedding is applied after concatenating text and motion tokens to encode relative positions across the whole sequence. Flow Matching, prompt rewriting and training HY-Motion 1.0 uses Flow Matching instead of standard denoising diffusion. The model learns a velocity field along a continuous path that interpolates between Gaussian noise and real motion data. During training, the objective is a mean squared error between predicted and ground truth velocities along this path. During inference, the learned ordinary differential equation is integrated from noise to a clean trajectory, which gives stable training for long sequences and fits the DiT architecture. A separate Duration Prediction and Prompt Rewrite module improves instruction following. It uses Qwen3 30B A3B as the base model and is trained on synthetic user style prompts generated from motion captions with a VLM and LLM pipeline, for example Gemini 2.5 Pro. This module predicts a suitable motion duration and rewrites informal prompts into normalized text that is easier for the DiT to follow. It is trained first with supervised fine tuning and then refined with Group Relative Policy Optimization, using Qwen3 235B A22B as a reward model that scores semantic consistency and duration plausibility. Training follows a 3 stage curriculum. Stage 1 performs large scale pretraining on the full 3,000 hour dataset to learn a broad motion prior and basic text motion alignment. Stage 2 fine tunes on the 400 hour high quality set to sharpen motion detail and improve semantic correctness with a smaller learning rate. Stage 3 applies reinforcement learning, first Direct Preference Optimization using 9,228 curated human preference pairs sampled from about 40,000 generated pairs, then Flow GRPO with a composite reward. The reward combines a semantic score from a Text Motion Retrieval model and a physics score that penalizes artifacts like foot sliding and root drift, under a KL regularization term to stay close to the supervised model. Benchmarks, scaling behavior and limitations For evaluation, the team builds a test set of over 2,000 prompts that span the 6 taxonomy categories and include simple, concurrent and sequential actions. Human raters score instruction following and motion quality on a scale from 1 to 5. HY-Motion 1.0 reaches an average instruction following score of 3.24 and an SSAE score of 78.6 percent. Baseline text-to-motion systems such as DART, LoM, GoToZero and MoMask achieve scores between 2.17 and 2.31 with SSAE between 42.7 percent and 58.0 percent. For motion quality, HY-Motion 1.0 reaches 3.43 on average versus 3.11 for the best baseline. Scaling experiments study DiT models with 0.05B, 0.46B, 0.46B trained only on 400 hours and 1B parameters. Instruction following improves steadily with model size, with the 1B model reaching an average of 3.34. Motion quality saturates around the 0.46B scale, where the 0.46B and 1B models reach similar averages between 3.26 and 3.34. Comparison of the 0.46B model trained on 3,000 hours and the 0.46B model trained only on 400 hours shows that larger data volume is key for instruction alignment, while high quality curation mainly improves realism. Key Takeaways Billion scale DiT Flow Matching for motion: HY-Motion 1.0 is the first Diffusion Transformer based Flow Matching model scaled to the 1B parameter level specifically for text to 3D human motion, targeting high fidelity instruction following across diverse actions. Large scale, curated motion corpus: The model is pretrained on over 3,000 hours of reconstructed, mocap and animation motion data and fine tuned on a 400 hour high quality subset, all retargeted to a unified SMPL H skeleton and organized into more than 200 motion categories. Hybrid DiT architecture with strong text conditioning: HY-Motion 1.0 uses a hybrid dual stream and single stream DiT with asymmetric attention, narrow band temporal attention and dual text encoders, Qwen3 8B and CLIP L, to fuse token level and global semantics into motion trajectories. RL aligned prompt rewrite and training pipeline: A dedicated Qwen3 30B based module predicts motion duration and rewrites user prompts, and the DiT is further aligned with Direct Preference Optimization and Flow GRPO using semantic and physics rewards, which improves realism and instruction following beyond supervised training. Check out the Paper and Full Codes here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching appeared first on MarkTechP […] -
admin wrote a new post 2 months, 2 weeks ago
Why inventing new emotions feels so goodHave you ever felt “velvetmist”? It’s a “complex and subtle emotion that elicits feelings of comfort, […]
-
admin wrote a new post 2 months, 2 weeks ago
A Coding Implementation of an OpenAI-Assisted Privacy-Preserving Federated Fraud Detection System from Scratch Using Lightweight PyTorch SimulationsIn this tutorial, we demonstrate how we simulate a privacy-preserving fraud detection system using Federated Learning without relying on heavyweight frameworks or complex infrastructure. We build a clean, CPU-friendly setup that mimics ten independent banks, each training a local fraud-detection model on its own highly imbalanced transaction data. We coordinate these local updates through a simple FedAvg aggregation loop, allowing us to improve a global model while ensuring that no raw transaction data ever leaves a client. Alongside this, we integrate OpenAI to support post-training analysis and risk-oriented reporting, demonstrating how federated learning outputs can be translated into decision-ready insights. Check out the Full Codes here. Copy CodeCopiedUse a different Browser!pip -q install torch scikit-learn numpy openai import time, random, json, os, getpass import numpy as np import torch import torch.nn as nn from torch.utils.data import DataLoader, TensorDataset from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import roc_auc_score, average_precision_score, accuracy_score from openai import OpenAI SEED = 7 random.seed(SEED); np.random.seed(SEED); torch.manual_seed(SEED) DEVICE = torch.device(“cpu”) print(“Device:”, DEVICE) We set up the execution environment and import all required libraries for data generation, modeling, evaluation, and reporting. We also fix random seeds and the device configuration to ensure our federated simulation remains deterministic and reproducible on CPU. Check out the Full Codes here. Copy CodeCopiedUse a different BrowserX, y = make_classification( n_samples=60000, n_features=30, n_informative=18, n_redundant=8, weights=[0.985, 0.015], class_sep=1.5, flip_y=0.01, random_state=SEED ) X = X.astype(np.float32) y = y.astype(np.int64) X_train_full, X_test, y_train_full, y_test = train_test_split( X, y, test_size=0.2, stratify=y, random_state=SEED ) server_scaler = StandardScaler() X_train_full_s = server_scaler.fit_transform(X_train_full).astype(np.float32) X_test_s = server_scaler.transform(X_test).astype(np.float32) test_loader = DataLoader( TensorDataset(torch.from_numpy(X_test_s), torch.from_numpy(y_test)), batch_size=1024, shuffle=False ) We generate a highly imbalanced, credit-card-like fraud dataset & split it into training & test sets. We standardize the server-side data and prepare a global test loader that allows us to consistently evaluate the aggregated model after each federated round. Check out the Full Codes here. Copy CodeCopiedUse a different Browserdef dirichlet_partition(y, n_clients=10, alpha=0.35): classes = np.unique(y) idx_by_class = [np.where(y == c)[0] for c in classes] client_idxs = [[] for _ in range(n_clients)] for idxs in idx_by_class: np.random.shuffle(idxs) props = np.random.dirichlet(alpha * np.ones(n_clients)) cuts = (np.cumsum(props) * len(idxs)).astype(int) prev = 0 for cid, cut in enumerate(cuts): client_idxs[cid].extend(idxs[prev:cut].tolist()) prev = cut return [np.array(ci, dtype=np.int64) for ci in client_idxs] NUM_CLIENTS = 10 client_idxs = dirichlet_partition(y_train_full, NUM_CLIENTS, 0.35) def make_client_split(X, y, idxs): Xi, yi = X[idxs], y[idxs] if len(np.unique(yi)) = 0.5).astype(int)) } def train_local(model, loader, lr): opt = torch.optim.Adam(model.parameters(), lr=lr) bce = nn.BCEWithLogitsLoss() model.train() for xb, yb in loader: opt.zero_grad() loss = bce(model(xb), yb.float()) loss.backward() opt.step() We define the neural network used for fraud detection along with utility functions for training, evaluation, and weight exchange. We implement lightweight local optimization and metric computation to keep client-side updates efficient and easy to reason about. Check out the Full Codes here. Copy CodeCopiedUse a different Browserdef fedavg(weights, sizes): total = sum(sizes) return [ sum(w[i] * (s / total) for w, s in zip(weights, sizes)) for i in range(len(weights[0])) ] ROUNDS = 10 LR = 5e-4 global_model = FraudNet(X_train_full.shape[1]) global_weights = get_weights(global_model) for r in range(1, ROUNDS + 1): client_weights, client_sizes = [], [] for cid in range(NUM_CLIENTS): local = FraudNet(X_train_full.shape[1]) set_weights(local, global_weights) train_local(local, client_loaders[cid][0], LR) client_weights.append(get_weights(local)) client_sizes.append(len(client_loaders[cid][0].dataset)) global_weights = fedavg(client_weights, client_sizes) set_weights(global_model, global_weights) metrics = evaluate(global_model, test_loader) print(f”Round {r}: {metrics}”) We orchestrate the federated learning process by iteratively training local client models and aggregating their parameters using FedAvg. We evaluate the global model after each round to monitor convergence and understand how collective learning improves fraud detection performance. Check out the Full Codes here. Copy CodeCopiedUse a different BrowserOPENAI_API_KEY = getpass.getpass(“Enter OPENAI_API_KEY (input hidden): “).strip() if OPENAI_API_KEY: os.environ[“OPENAI_API_KEY”] = OPENAI_API_KEY client = OpenAI() summary = { “rounds”: ROUNDS, “num_clients”: NUM_CLIENTS, “final_metrics”: metrics, “client_sizes”: [len(client_loaders[c][0].dataset) for c in range(NUM_CLIENTS)], “client_fraud_rates”: [float(client_data[c][1].mean()) for c in range(NUM_CLIENTS)] } prompt = ( “Write a concise internal fraud-risk report.n” “Include executive summary, metric interpretation, risks, and next steps.nn” + json.dumps(summary, indent=2) ) resp = client.responses.create(model=”gpt-5.2″, input=prompt) print(resp.output_text) We transform the technical results into a concise analytical report using an external language model. We securely accept the API key via keyboard input and generate decision-oriented insights that summarize performance, risks, and recommended next steps. In conclusion, we showed how to implement federated learning from first principles in a Colab notebook while remaining stable, interpretable, and realistic. We observed how extreme data heterogeneity across clients influences convergence and why careful aggregation and evaluation are critical in fraud-detection settings. We also extended the workflow by generating an automated risk-team report, demonstrating how analytical results can be translated into decision-ready insights. At last, we presented a practical blueprint for experimenting with federated fraud models that emphasizes privacy awareness, simplicity, and real-world relevance. Check out the Full Codes here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post A Coding Implementation of an OpenAI-Assisted Privacy-Preserving Federated Fraud Detection System from Scratch Using Lightweight PyTorch Simulations appeared first on MarkTec […]
-
admin wrote a new post 2 months, 2 weeks ago
-
admin wrote a new post 2 months, 2 weeks ago
Yay, Digital Hodge-Podge! The Best Collage Apps For InstagramI’m going to say this gently: Collages aren’t that cool anymore. There was once a time (circa 2014) when they were everywhere online, but take a…
-
admin wrote a new post 2 months, 2 weeks ago
10 Awesome Docker Projects for BeginnersAs a developer, tell me if you relate to this – Docker commands are easy to understand but difficult to a […]
-
admin wrote a new post 2 months, 2 weeks ago
What is Chain of Thought (CoT) Prompting?The core idea behind Chain of Thought (CoT) is to encourage an AI model to reason step by step before […]
-
admin wrote a new post 2 months, 2 weeks ago
-
admin wrote a new post 2 months, 2 weeks ago
-
admin wrote a new post 2 months, 2 weeks ago
The ascent of the AI therapistWe’re in the midst of a global mental-health crisis. More than a billion people worldwide suffer from a me […]
-
admin wrote a new post 2 months, 2 weeks ago
What is F1 Score in Machine Learning?In machine learning and data science, evaluating a model is as important as building it. Accuracy is often […]
-
admin wrote a new post 2 months, 2 weeks ago
Influencer Marketplaces: How They Work, Top Options, and More Things You Need to KnowInfluencer marketplaces, collab hubs, brand portals — they go by many names, but serve the same purpose: being a place where creators and brands can work…
-
admin wrote a new post 2 months, 2 weeks ago
Track and Monitor AI Agents Using MLflow: Complete Guide for Agentic SystemsMore machine learning systems now rely on AI agents, which makes […]
-
admin wrote a new post 2 months, 2 weeks ago
-
admin wrote a new post 2 months, 2 weeks ago
Bangladesh’s garment-making industry is getting greenerPollution from textile production—dyes, chemicals, and heavy metals like lead and c […]
-
admin wrote a new post 2 months, 2 weeks ago
NVIDIA AI Researchers Release NitroGen: An Open Vision Action Foundation Model For Generalist Gaming Agents
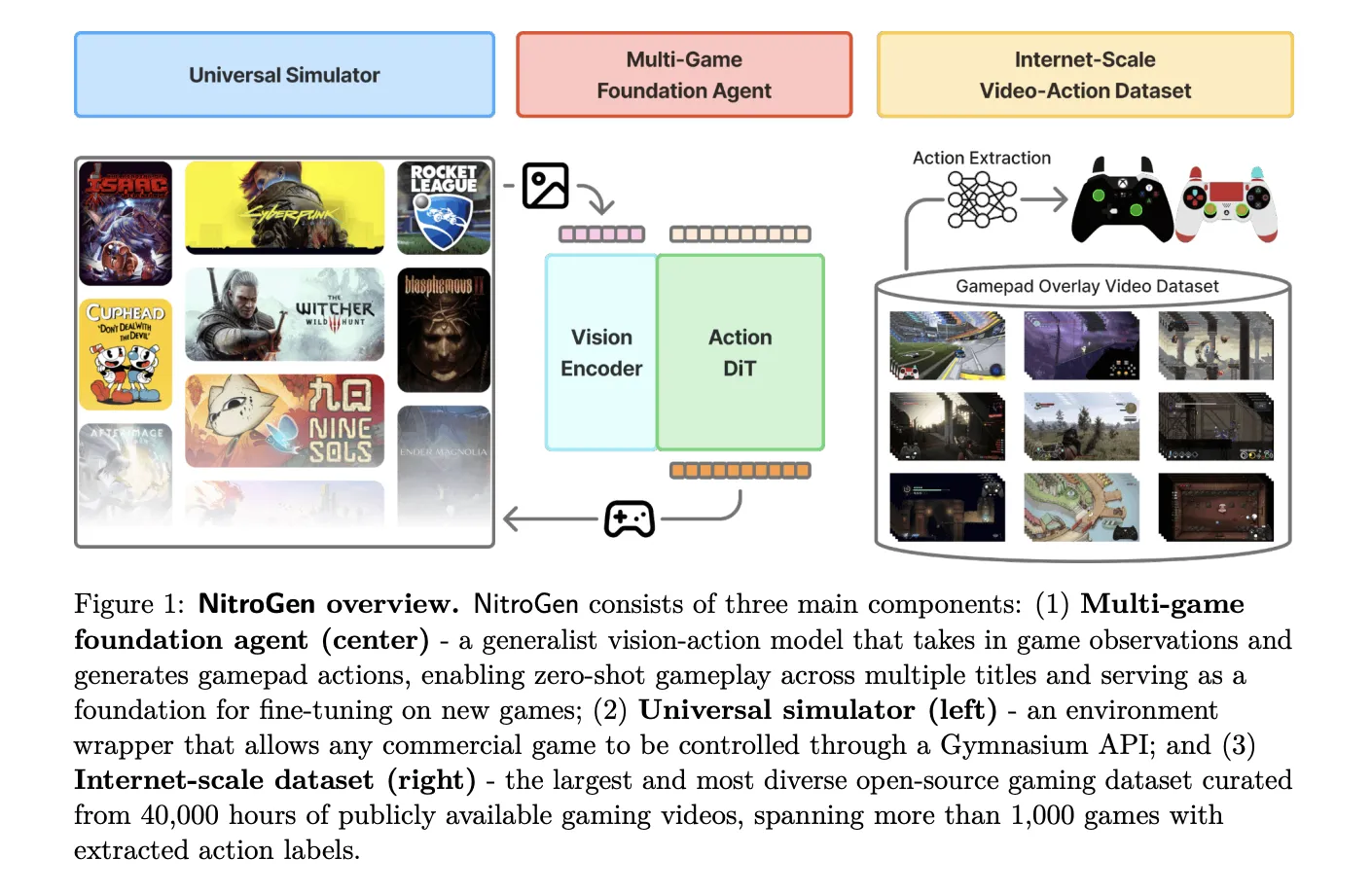 NVIDIA AI research team released […]
NVIDIA AI research team released […] -
admin wrote a new post 2 months, 2 weeks ago
Google A2UI Explained: How AI Agents Build Secure, Native User InterfacesWe have entered the time of multi-agent artificial intelligence. However, […]
- Load More
admin
Last active: Active 3 months ago
SHARE:
Comments: 0
Likes: 0
Submitted: 1048
Friends: 0
User Rating: Be the first one!
Adsterra
🔥 Top Offers (Limited Time)
