
-
admin wrote a new post 1 day, 17 hours ago
The Download: Pokémon Go to train world models, and the US-China race to find aliensThis is today’s edition of The Download, our weekday n […]
-
admin wrote a new post 1 day, 20 hours ago
Rakuten fixes issues twice as fast with CodexRakuten uses Codex, the coding agent from OpenAI, to ship software faster and safer, reducing MTTR 50%, automating CI/CD reviews, and delivering full-stack builds in weeks.
-
admin wrote a new post 1 day, 23 hours ago
Wayfair boosts catalog accuracy and support speed with OpenAIWayfair uses OpenAI models to improve ecommerce support and product catalog accuracy, automating ticket triage and enhancing millions of product attributes at scale.
-
admin wrote a new post 2 days, 5 hours ago
Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space
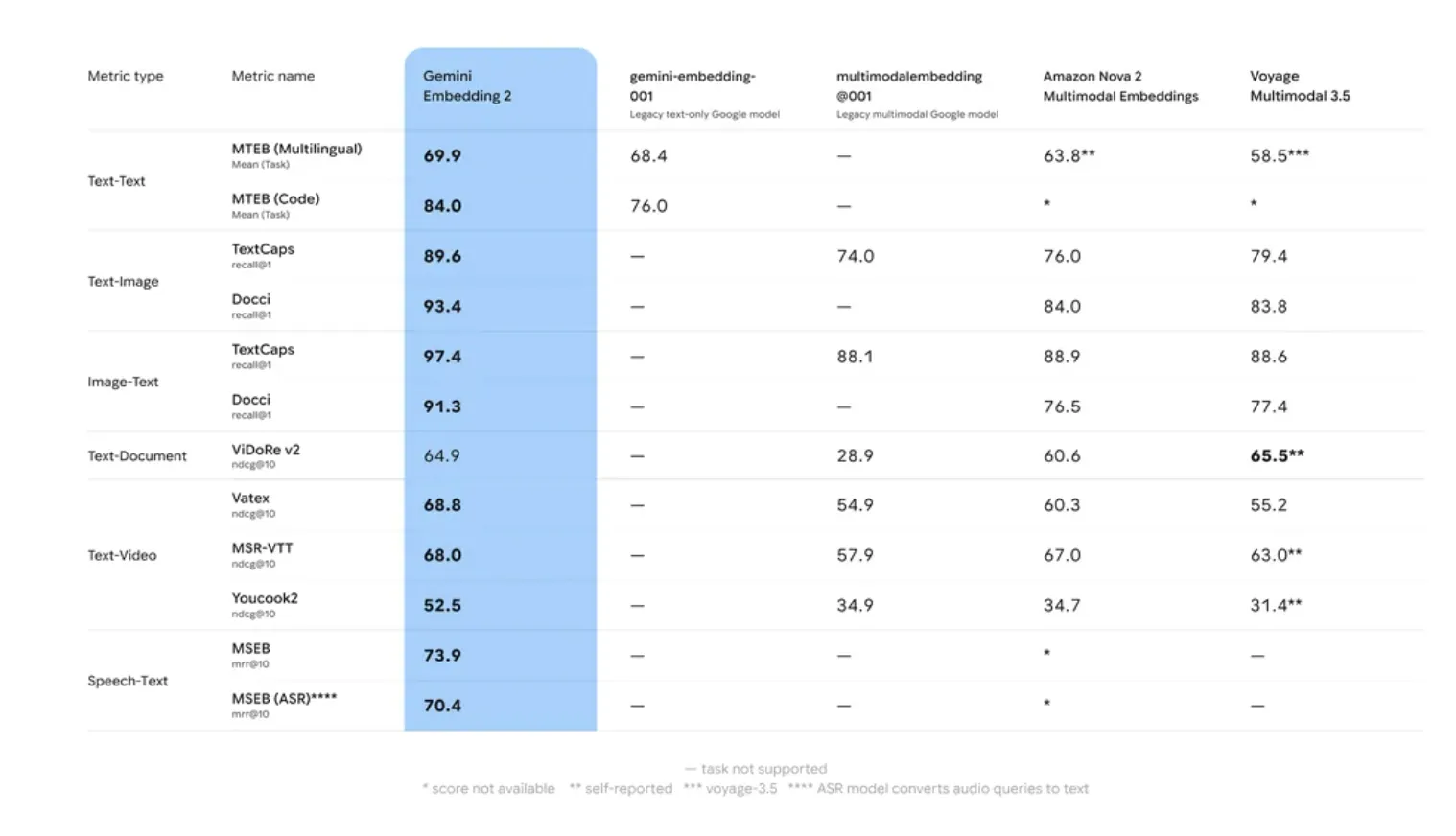 Google expanded its Gemini model family with the release of Gemini Embedding 2. This second-generation model succeeds the text-only gemini-embedding-001 and is designed specifically to address the high-dimensional storage and cross-modal retrieval challenges faced by AI developers building production-grade Retrieval-Augmented Generation (RAG) systems. The Gemini Embedding 2 release marks a significant technical shift in how embedding models are architected, moving away from modality-specific pipelines toward a unified, natively multimodal latent space. Native Multimodality and Interleaved Inputs The primary architectural advancement in Gemini Embedding 2 is its ability to map five distinct media types—Text, Image, Video, Audio, and PDF—into a single, high-dimensional vector space. This eliminates the need for complex pipelines that previously required separate models for different data types, such as CLIP for images and BERT-based models for text. The model supports interleaved inputs, allowing developers to combine different modalities in a single embedding request. This is particularly relevant for use cases where text alone does not provide sufficient context. The technical limits for these inputs are defined as: Text: Up to 8,192 tokens per request. Images: Up to 6 images (PNG, JPEG, WebP, HEIC/HEIF). Video: Up to 120 seconds of video (MP4, MOV, etc.). Audio: Up to 80 seconds of native audio (MP3, WAV, etc.) without requiring a separate transcription step. Documents: Up to 6 pages of PDF files. By processing these inputs natively, Gemini Embedding 2 captures the semantic relationships between a visual frame in a video and the spoken dialogue in an audio track, projecting them as a single vector that can be compared against text queries using standard distance metrics like Cosine Similarity. Efficiency via Matryoshka Representation Learning (MRL) Storage and compute costs are often the primary bottlenecks in large-scale vector search. To mitigate this, Gemini Embedding 2 implements Matryoshka Representation Learning (MRL). Standard embedding models distribute semantic information evenly across all dimensions. If a developer truncates a 3,072-dimension vector to 768 dimensions, the accuracy typically collapses because the information is lost. In contrast, Gemini Embedding 2 is trained to pack the most critical semantic information into the earliest dimensions of the vector. The model defaults to 3,072 dimensions, but Google team has optimized three specific tiers for production use: 3,072: Maximum precision for complex legal, medical, or technical datasets. 1,536: A balance of performance and storage efficiency. 768: Optimized for low-latency retrieval and reduced memory footprint. Matryoshka Representation Learning (MRL) enables a ‘short-listing’ architecture. A system can perform a coarse, high-speed search across millions of items using the 768-dimension sub-vectors, then perform a precise re-ranking of the top results using the full 3,072-dimension embeddings. This reduces the computational overhead of the initial retrieval stage without sacrificing the final accuracy of the RAG pipeline. Benchmarking: MTEB and Long-Context Retrieval Google AI’s internal evaluation and performance on the Massive Text Embedding Benchmark (MTEB) indicate that Gemini Embedding 2 outperforms its predecessor in two specific areas: Retrieval Accuracy and Robustness to Domain Shift. Many embedding models suffer from ‘domain drift,’ where accuracy drops when moving from generic training data (like Wikipedia) to specialized domains (like proprietary codebases). Gemini Embedding 2 utilized a multi-stage training process involving diverse datasets to ensure higher zero-shot performance across specialized tasks. The model’s 8,192-token window is a critical specification for RAG. It allows for the embedding of larger ‘chunks’ of text, which preserves the context necessary for resolving coreferences and long-range dependencies within a document. This reduces the likelihood of ‘context fragmentation,’ a common issue where a retrieved chunk lacks the information needed for the LLM to generate a coherent answer. Key Takeaways Native Multimodality: Gemini Embedding 2 supports five distinct media types—Text, Image, Video, Audio, and PDF—within a unified vector space. This allows for interleaved inputs (e.g., an image combined with a text caption) to be processed as a single embedding without separate model pipelines. Matryoshka Representation Learning (MRL): The model is architected to store the most critical semantic information in the early dimensions of a vector. While it defaults to 3,072 dimensions, it supports efficient truncation to 1,536 or 768 dimensions with minimal loss in accuracy, reducing storage costs and increasing retrieval speed. Expanded Context and Performance: The model features an 8,192-token input window, allowing for larger text ‘chunks’ in RAG pipelines. It shows significant performance improvements on the Massive Text Embedding Benchmark (MTEB), specifically in retrieval accuracy and handling specialized domains like code or technical documentation. Task-Specific Optimization: Developers can use task_type parameters (such as RETRIEVAL_QUERY, RETRIEVAL_DOCUMENT, or CLASSIFICATION) to provide hints to the model. This optimizes the vector’s mathematical properties for the specific operation, improving the “hit rate” in semantic search. Check out Technical details, in Public Preview via the Gemini API and Vertex AI. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space appeared first on MarkTech […]
Google expanded its Gemini model family with the release of Gemini Embedding 2. This second-generation model succeeds the text-only gemini-embedding-001 and is designed specifically to address the high-dimensional storage and cross-modal retrieval challenges faced by AI developers building production-grade Retrieval-Augmented Generation (RAG) systems. The Gemini Embedding 2 release marks a significant technical shift in how embedding models are architected, moving away from modality-specific pipelines toward a unified, natively multimodal latent space. Native Multimodality and Interleaved Inputs The primary architectural advancement in Gemini Embedding 2 is its ability to map five distinct media types—Text, Image, Video, Audio, and PDF—into a single, high-dimensional vector space. This eliminates the need for complex pipelines that previously required separate models for different data types, such as CLIP for images and BERT-based models for text. The model supports interleaved inputs, allowing developers to combine different modalities in a single embedding request. This is particularly relevant for use cases where text alone does not provide sufficient context. The technical limits for these inputs are defined as: Text: Up to 8,192 tokens per request. Images: Up to 6 images (PNG, JPEG, WebP, HEIC/HEIF). Video: Up to 120 seconds of video (MP4, MOV, etc.). Audio: Up to 80 seconds of native audio (MP3, WAV, etc.) without requiring a separate transcription step. Documents: Up to 6 pages of PDF files. By processing these inputs natively, Gemini Embedding 2 captures the semantic relationships between a visual frame in a video and the spoken dialogue in an audio track, projecting them as a single vector that can be compared against text queries using standard distance metrics like Cosine Similarity. Efficiency via Matryoshka Representation Learning (MRL) Storage and compute costs are often the primary bottlenecks in large-scale vector search. To mitigate this, Gemini Embedding 2 implements Matryoshka Representation Learning (MRL). Standard embedding models distribute semantic information evenly across all dimensions. If a developer truncates a 3,072-dimension vector to 768 dimensions, the accuracy typically collapses because the information is lost. In contrast, Gemini Embedding 2 is trained to pack the most critical semantic information into the earliest dimensions of the vector. The model defaults to 3,072 dimensions, but Google team has optimized three specific tiers for production use: 3,072: Maximum precision for complex legal, medical, or technical datasets. 1,536: A balance of performance and storage efficiency. 768: Optimized for low-latency retrieval and reduced memory footprint. Matryoshka Representation Learning (MRL) enables a ‘short-listing’ architecture. A system can perform a coarse, high-speed search across millions of items using the 768-dimension sub-vectors, then perform a precise re-ranking of the top results using the full 3,072-dimension embeddings. This reduces the computational overhead of the initial retrieval stage without sacrificing the final accuracy of the RAG pipeline. Benchmarking: MTEB and Long-Context Retrieval Google AI’s internal evaluation and performance on the Massive Text Embedding Benchmark (MTEB) indicate that Gemini Embedding 2 outperforms its predecessor in two specific areas: Retrieval Accuracy and Robustness to Domain Shift. Many embedding models suffer from ‘domain drift,’ where accuracy drops when moving from generic training data (like Wikipedia) to specialized domains (like proprietary codebases). Gemini Embedding 2 utilized a multi-stage training process involving diverse datasets to ensure higher zero-shot performance across specialized tasks. The model’s 8,192-token window is a critical specification for RAG. It allows for the embedding of larger ‘chunks’ of text, which preserves the context necessary for resolving coreferences and long-range dependencies within a document. This reduces the likelihood of ‘context fragmentation,’ a common issue where a retrieved chunk lacks the information needed for the LLM to generate a coherent answer. Key Takeaways Native Multimodality: Gemini Embedding 2 supports five distinct media types—Text, Image, Video, Audio, and PDF—within a unified vector space. This allows for interleaved inputs (e.g., an image combined with a text caption) to be processed as a single embedding without separate model pipelines. Matryoshka Representation Learning (MRL): The model is architected to store the most critical semantic information in the early dimensions of a vector. While it defaults to 3,072 dimensions, it supports efficient truncation to 1,536 or 768 dimensions with minimal loss in accuracy, reducing storage costs and increasing retrieval speed. Expanded Context and Performance: The model features an 8,192-token input window, allowing for larger text ‘chunks’ in RAG pipelines. It shows significant performance improvements on the Massive Text Embedding Benchmark (MTEB), specifically in retrieval accuracy and handling specialized domains like code or technical documentation. Task-Specific Optimization: Developers can use task_type parameters (such as RETRIEVAL_QUERY, RETRIEVAL_DOCUMENT, or CLASSIFICATION) to provide hints to the model. This optimizes the vector’s mathematical properties for the specific operation, improving the “hit rate” in semantic search. Check out Technical details, in Public Preview via the Gemini API and Vertex AI. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Google AI Introduces Gemini Embedding 2: A Multimodal Embedding Model that Lets Your Bring Text, Images, Video, Audio, and Docs into the Embedding Space appeared first on MarkTech […] -
admin wrote a new post 2 days, 5 hours ago
-
admin wrote a new post 2 days, 16 hours ago
Top 7 Free SQL Courses with CertificatesFor different learning styles, goals, and comfort levels, finding a SQL course that matches how you learn […]
-
admin wrote a new post 2 days, 16 hours ago
Claude Flow: The AI Orchestration Framework Redefining Multi-Agent Automation Claude Flow is an open-source orchestration framework designed to run […]
-
admin wrote a new post 2 days, 16 hours ago
NVIDIA AI Releases Nemotron-Terminal: A Systematic Data Engineering Pipeline for Scaling LLM Terminal Agents
 The race to build autonomous AI agents […]
The race to build autonomous AI agents […] -
admin wrote a new post 2 days, 16 hours ago
Being a Bad Bitch Is a Full-Time Job (And the Internet Clock Never Punches Out)The collision between ambition, visibility, and intimacy in 2026 is real. Being online, living authentically, building an audience, and still trying to be a person do…
-
admin wrote a new post 2 days, 16 hours ago
How Pokémon Go is giving delivery robots an inch-perfect view of the worldPokémon Go was the world’s first augmented-reality megahit. Released in […]
-
admin wrote a new post 2 days, 17 hours ago
Prioritizing energy intelligence for sustainable growth
 Loudoun County, Virginia, once known for its pastoral scenery and proximity to Washington, […]
Loudoun County, Virginia, once known for its pastoral scenery and proximity to Washington, […] -
admin wrote a new post 2 days, 20 hours ago
Improving instruction hierarchy in frontier LLMsIH-Challenge trains models to prioritize trusted instructions, improving instruction hierarchy, safety steerability, and resistance to prompt injection attacks.
-
admin wrote a new post 2 days, 23 hours ago
New ways to learn math and science in ChatGPTChatGPT introduces interactive visual explanations for math and science, helping students explore formulas, variables, and concepts in real time.
-
admin wrote a new post 3 days, 5 hours ago
-
admin wrote a new post 3 days, 5 hours ago
-
admin wrote a new post 3 days, 17 hours ago
Top 7 Free Anthropic AI Academy Courses with CertificatesHaving the right certificate can make all the difference. But with so many out there, […]
-
admin wrote a new post 3 days, 17 hours ago
-
admin wrote a new post 3 days, 17 hours ago
-
admin wrote a new post 3 days, 17 hours ago
Debunking Myths About Instagram Automation: What Manychat Does DifferentlyThis edition of myth-busting sadly won’t involve exploding anything MythBusters style — you can always use your imagination if it’s that important to you — but…
-
admin wrote a new post 3 days, 17 hours ago
How AI is turning the Iran conflict into theaterThis story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like […]
- Load More
admin
Last active: Active 3 months ago
Comments: 0
Likes: 0
Submitted: 1041
Friends: 0
User Rating: Be the first one!

