
-
admin wrote a new post 1 month ago
Harness Engineering with LangChain DeepAgents and LangSmithStruggling to make AI systems reliable and consistent? Many teams face the same […]
-
admin wrote a new post 1 month ago
Testing LLMs on superconductivity research questionsEducation Innovation
-
admin wrote a new post 1 month ago
-
admin wrote a new post 1 month ago
How to Set Up a Virtual Call Centre
 As customer bases grow, so does the volume of enquiries that contact centres have to handle. For many […]
As customer bases grow, so does the volume of enquiries that contact centres have to handle. For many […] -
admin wrote a new post 1 month ago
How Much is a Missed Connection REALLY Costing You?There’s a rush when you open Instagram, tap your inbox, and see something unexpected: an opportunity. It could be from another creator or brand wanting to…
-
admin wrote a new post 1 month ago
How Much Money Can You Make on TikTok?So, you want to make money on TikTok, eh? It’s the dream for a lot of people these days, and I get why: You just need…
-
admin wrote a new post 1 month ago
Where OpenAI’s technology could show up in IranThis story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like […]
-
admin wrote a new post 1 month ago
Nurturing agentic AI beyond the toddler stageParents of young children face a lot of fears about developmental milestones, from infancy through […]
-
admin wrote a new post 1 month ago
Why Codex Security Doesn’t Include a SAST ReportA deep dive into why Codex Security doesn’t rely on traditional SAST, instead using AI-driven constraint reasoning and validation to find real vulnerabilities with fewer false positives.
-
admin wrote a new post 1 month ago
Moonshot AI Releases 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔 to Replace Fixed Residual Mixing with Depth-Wise Attention for Better Scaling in Transformers
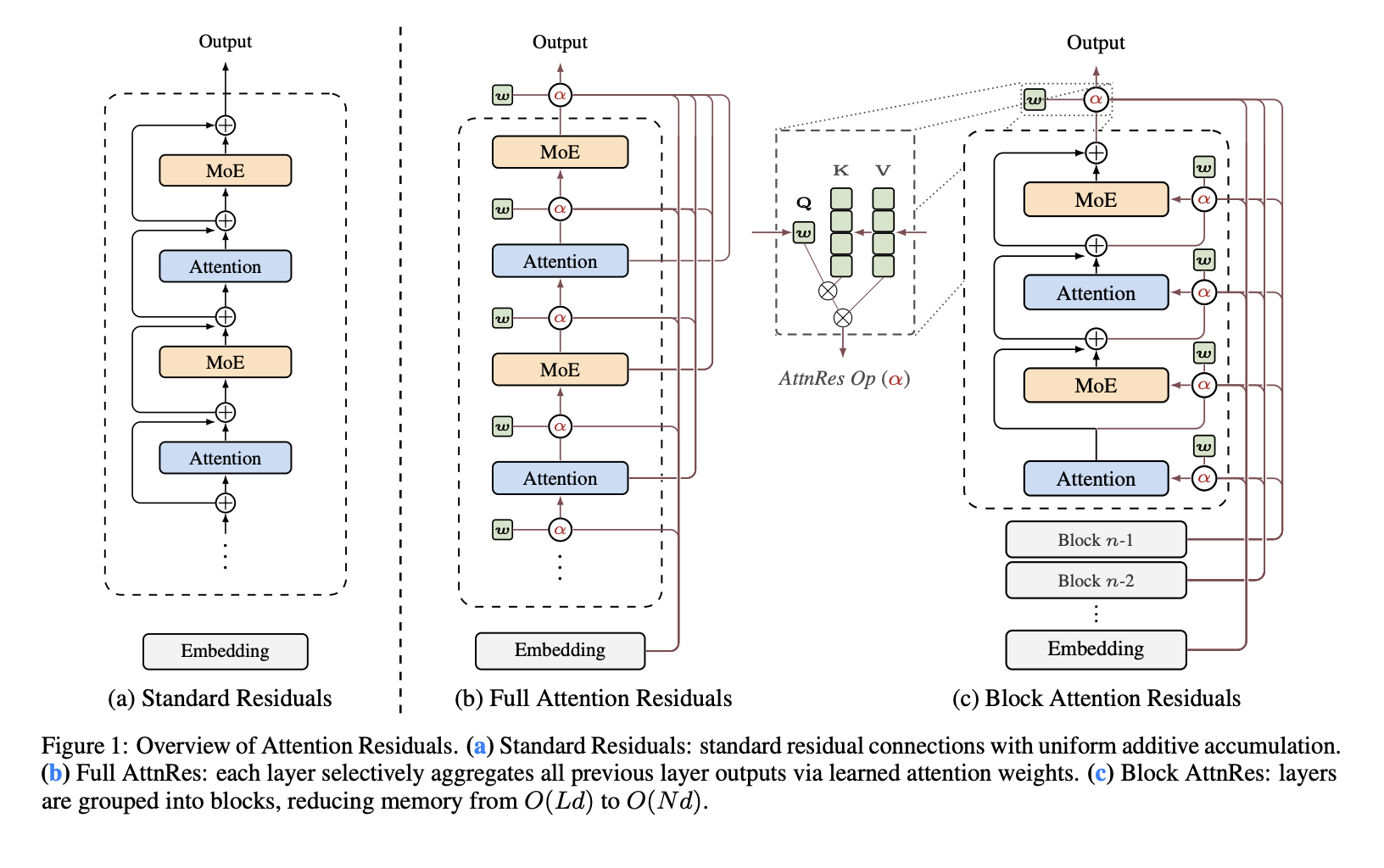 Residual connections are one of the least questioned parts of modern Transformer design. In PreNorm architectures, each layer adds its output back into a running hidden state, which keeps optimization stable and allows deep models to train. Moonshot AI researchers argue that this standard mechanism also introduces a structural problem: all prior layer outputs are accumulated with fixed unit weights, which causes hidden-state magnitude to grow with depth and progressively weakens the contribution of any single layer. The research team proposes Attention Residuals (AttnRes) as a drop-in replacement for standard residual accumulation. Instead of forcing every layer to consume the same uniformly mixed residual stream, AttnRes lets each layer aggregate earlier representations using softmax attention over depth. The input to layer (l) is a weighted sum of the token embedding and previous layer outputs, where the weights are computed over prior depth positions rather than over sequence positions. The core idea is simple: if attention improved sequence modeling by replacing fixed recurrence over time, a similar idea can be applied to the depth dimension of a network. Why Standard Residuals Become a Bottleneck The research team identified three issues with standard residual accumulation. First, there is no selective access: all layers receive the same aggregated state even though attention layers and feed-forward or MoE layers may benefit from different mixtures of earlier information. Second, there is irreversible loss: once information is blended into a single residual stream, later layers cannot selectively recover specific earlier representations. Third, there is output growth: deeper layers tend to produce larger outputs to remain influential inside an ever-growing accumulated state, which can destabilize training. This is the research team’s main framing: standard residuals behave like a compressed recurrence over layers. AttnRes replaces that fixed recurrence with explicit attention over previous layer outputs. Full AttnRes: Attention Over All Previous Layers In Full AttnRes, each layer computes attention weights over all preceding depth sources. The default design does not use an input-conditioned query. Instead, each layer has a learned layer-specific pseudo-query vector wl ∈ Rd, while keys and values come from the token embedding and previous layer outputs after RMSNorm. The RMSNorm step is important because it prevents large-magnitude layer outputs from dominating the depth-wise attention weights. Full AttnRes is straightforward, but it increases cost. Per token, it requires O(L2 d) arithmetic and (O(Ld)) memory to store layer outputs. In standard training this memory largely overlaps with activations already needed for backpropagation, but under activation re-computation and pipeline parallelism the overhead becomes more significant because those earlier outputs must remain available and may need to be transmitted across stages. Block AttnRes: A Practical Variant for Large Models To make the method usable at scale, Moonshot AI research team introduces Block AttnRes. Instead of attending over every earlier layer output, the model partitions layers into N blocks. Within each block, outputs are accumulated into a single block representation, and attention is applied only over those block-level representations plus the token embedding. This reduces memory and communication overhead from O(Ld) to O(Nd). The research team describes cache-based pipeline communication and a two-phase computation strategy that make Block AttnRes practical in distributed training and inference. This results in less than 4% training overhead under pipeline parallelism, while the repository reports less than 2% inference latency overhead on typical workloads. Scaling Results The research team evaluates five model sizes and compares three variants at each size: a PreNorm baseline, Full AttnRes, and Block AttnRes with about eight blocks. All variants within each size group share the same hyperparameters chosen under the baseline, which the research team note makes the comparison conservative. The fitted scaling laws are reported as: Baseline: L = 1.891 x C-0.057Block AttnRes: L = 1.870 x C-0.058Full AttnRes: L = 1.865 x C-0.057 The practical implication is that AttnRes achieves lower validation loss across the tested compute range, and the Block AttnRes matches the loss of a baseline trained with about 1.25× more compute. Integration into Kimi Linear Moonshot AI also integrates AttnRes into Kimi Linear, its MoE architecture with 48B total parameters and 3B activated parameters, and pre-trains it on 1.4T tokens. According to the research paper, AttnRes mitigates PreNorm dilution by keeping output magnitudes more bounded across depth and distributing gradients more uniformly across layers. Another implementation detail is that all pseudo-query vectors are initialized to zero so the initial attention weights are uniform across source layers, effectively reducing AttnRes to equal-weight averaging at the start of training and avoiding early instability. On downstream evaluation, the reported gains are consistent across all listed tasks. It reports improvements from 73.5 to 74.6 on MMLU, 36.9 to 44.4 on GPQA-Diamond, 76.3 to 78.0 on BBH, 53.5 to 57.1 on Math, 59.1 to 62.2 on HumanEval, 72.0 to 73.9 on MBPP, 82.0 to 82.9 on CMMLU, and 79.6 to 82.5 on C-Eval. Key Takeaways Attention Residuals replaces fixed residual accumulation with softmax attention over previous layers. The default AttnRes design uses a learned layer-specific pseudo-query, not an input-conditioned query. Block AttnRes makes the method practical by reducing depth-wise memory and communication from O(Ld) to O(Nd). Moonshot research teamreports lower scaling loss than the PreNorm baseline, with Block AttnRes matching about 1.25× more baseline compute. In Kimi Linear, AttnRes improves results across reasoning, coding, and evaluation benchmarks with limited overhead. Check out Paper and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Moonshot AI Releases 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔 to Replace Fixed Residual Mixing with Depth-Wise Attention for Better Scal […]
Residual connections are one of the least questioned parts of modern Transformer design. In PreNorm architectures, each layer adds its output back into a running hidden state, which keeps optimization stable and allows deep models to train. Moonshot AI researchers argue that this standard mechanism also introduces a structural problem: all prior layer outputs are accumulated with fixed unit weights, which causes hidden-state magnitude to grow with depth and progressively weakens the contribution of any single layer. The research team proposes Attention Residuals (AttnRes) as a drop-in replacement for standard residual accumulation. Instead of forcing every layer to consume the same uniformly mixed residual stream, AttnRes lets each layer aggregate earlier representations using softmax attention over depth. The input to layer (l) is a weighted sum of the token embedding and previous layer outputs, where the weights are computed over prior depth positions rather than over sequence positions. The core idea is simple: if attention improved sequence modeling by replacing fixed recurrence over time, a similar idea can be applied to the depth dimension of a network. Why Standard Residuals Become a Bottleneck The research team identified three issues with standard residual accumulation. First, there is no selective access: all layers receive the same aggregated state even though attention layers and feed-forward or MoE layers may benefit from different mixtures of earlier information. Second, there is irreversible loss: once information is blended into a single residual stream, later layers cannot selectively recover specific earlier representations. Third, there is output growth: deeper layers tend to produce larger outputs to remain influential inside an ever-growing accumulated state, which can destabilize training. This is the research team’s main framing: standard residuals behave like a compressed recurrence over layers. AttnRes replaces that fixed recurrence with explicit attention over previous layer outputs. Full AttnRes: Attention Over All Previous Layers In Full AttnRes, each layer computes attention weights over all preceding depth sources. The default design does not use an input-conditioned query. Instead, each layer has a learned layer-specific pseudo-query vector wl ∈ Rd, while keys and values come from the token embedding and previous layer outputs after RMSNorm. The RMSNorm step is important because it prevents large-magnitude layer outputs from dominating the depth-wise attention weights. Full AttnRes is straightforward, but it increases cost. Per token, it requires O(L2 d) arithmetic and (O(Ld)) memory to store layer outputs. In standard training this memory largely overlaps with activations already needed for backpropagation, but under activation re-computation and pipeline parallelism the overhead becomes more significant because those earlier outputs must remain available and may need to be transmitted across stages. Block AttnRes: A Practical Variant for Large Models To make the method usable at scale, Moonshot AI research team introduces Block AttnRes. Instead of attending over every earlier layer output, the model partitions layers into N blocks. Within each block, outputs are accumulated into a single block representation, and attention is applied only over those block-level representations plus the token embedding. This reduces memory and communication overhead from O(Ld) to O(Nd). The research team describes cache-based pipeline communication and a two-phase computation strategy that make Block AttnRes practical in distributed training and inference. This results in less than 4% training overhead under pipeline parallelism, while the repository reports less than 2% inference latency overhead on typical workloads. Scaling Results The research team evaluates five model sizes and compares three variants at each size: a PreNorm baseline, Full AttnRes, and Block AttnRes with about eight blocks. All variants within each size group share the same hyperparameters chosen under the baseline, which the research team note makes the comparison conservative. The fitted scaling laws are reported as: Baseline: L = 1.891 x C-0.057Block AttnRes: L = 1.870 x C-0.058Full AttnRes: L = 1.865 x C-0.057 The practical implication is that AttnRes achieves lower validation loss across the tested compute range, and the Block AttnRes matches the loss of a baseline trained with about 1.25× more compute. Integration into Kimi Linear Moonshot AI also integrates AttnRes into Kimi Linear, its MoE architecture with 48B total parameters and 3B activated parameters, and pre-trains it on 1.4T tokens. According to the research paper, AttnRes mitigates PreNorm dilution by keeping output magnitudes more bounded across depth and distributing gradients more uniformly across layers. Another implementation detail is that all pseudo-query vectors are initialized to zero so the initial attention weights are uniform across source layers, effectively reducing AttnRes to equal-weight averaging at the start of training and avoiding early instability. On downstream evaluation, the reported gains are consistent across all listed tasks. It reports improvements from 73.5 to 74.6 on MMLU, 36.9 to 44.4 on GPQA-Diamond, 76.3 to 78.0 on BBH, 53.5 to 57.1 on Math, 59.1 to 62.2 on HumanEval, 72.0 to 73.9 on MBPP, 82.0 to 82.9 on CMMLU, and 79.6 to 82.5 on C-Eval. Key Takeaways Attention Residuals replaces fixed residual accumulation with softmax attention over previous layers. The default AttnRes design uses a learned layer-specific pseudo-query, not an input-conditioned query. Block AttnRes makes the method practical by reducing depth-wise memory and communication from O(Ld) to O(Nd). Moonshot research teamreports lower scaling loss than the PreNorm baseline, with Block AttnRes matching about 1.25× more baseline compute. In Kimi Linear, AttnRes improves results across reasoning, coding, and evaluation benchmarks with limited overhead. Check out Paper and Repo. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Moonshot AI Releases 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔 to Replace Fixed Residual Mixing with Depth-Wise Attention for Better Scal […] -
admin wrote a new post 1 month ago
IBM AI Releases Granite 4.0 1B Speech as a Compact Multilingual Speech Model for Edge AI and Translation PipelinesIBM has released Granite 4.0 1B […]
-
admin wrote a new post 1 month ago
RCS Business Messaging Use Cases By Industry
 Messaging has become one of the most important ways organisations communicate with customers, […]
Messaging has become one of the most important ways organisations communicate with customers, […] -
admin wrote a new post 1 month ago
Generative AI vs Agentic AI: From Creating Content to Taking ActionThe last two years were defined by a single word: Generative AI. Tools like […]
-
admin wrote a new post 1 month ago
A Coding Implementation to Design an Enterprise AI Governance System Using OpenClaw Gateway Policy Engines, Approval Workflows and Auditable Agent ExecutionIn this tutorial, we build an enterprise-grade AI governance system using OpenClaw and Python. We start by setting up the OpenClaw runtime and launching the OpenClaw Gateway so that our Python environment can interact with a real agent through the OpenClaw API. We then design a governance layer that classifies requests based on risk, enforces approval policies, and routes safe tasks to the OpenClaw agent for execution. By combining OpenClaw’s agent capabilities with policy controls, we demonstrate how organizations can safely deploy autonomous AI systems while maintaining visibility, traceability, and operational oversight. Copy CodeCopiedUse a different Browser!apt-get update -y !apt-get install -y curl !curl -fsSL https://deb.nodesource.com/setup_22.x | bash – !apt-get install -y nodejs !node -v !npm -v !npm install -g openclaw@latest !pip -q install requests pandas pydantic import os import json import time import uuid import secrets import subprocess import getpass from pathlib import Path from typing import Dict, Any from dataclasses import dataclass, asdict from datetime import datetime, timezone import requests import pandas as pd from pydantic import BaseModel, Field try: from google.colab import userdata OPENAI_API_KEY = userdata.get(“OPENAI_API_KEY”) except Exception: OPENAI_API_KEY = None if not OPENAI_API_KEY: OPENAI_API_KEY = os.environ.get(“OPENAI_API_KEY”) if not OPENAI_API_KEY: OPENAI_API_KEY = getpass.getpass(“Enter your OpenAI API key (hidden input): “).strip() assert OPENAI_API_KEY != “”, “API key cannot be empty.” OPENCLAW_HOME = Path(“/root/.openclaw”) OPENCLAW_HOME.mkdir(parents=True, exist_ok=True) WORKSPACE = OPENCLAW_HOME / “workspace” WORKSPACE.mkdir(parents=True, exist_ok=True) GATEWAY_TOKEN = secrets.token_urlsafe(48) GATEWAY_PORT = 18789 GATEWAY_URL = f”http://127.0.0.1:{GATEWAY_PORT}” We prepare the environment required to run the OpenClaw-based governance system. We install Node.js, the OpenClaw CLI, and the required Python libraries so our notebook can interact with the OpenClaw Gateway and supporting tools. We also securely collect the OpenAI API key via a hidden terminal prompt and initialize the directories and variables required for runtime configuration. Copy CodeCopiedUse a different Browserconfig = { “env”: { “OPENAI_API_KEY”: OPENAI_API_KEY }, “agents”: { “defaults”: { “workspace”: str(WORKSPACE), “model”: { “primary”: “openai/gpt-4.1-mini” } } }, “gateway”: { “mode”: “local”, “port”: GATEWAY_PORT, “bind”: “loopback”, “auth”: { “mode”: “token”, “token”: GATEWAY_TOKEN }, “http”: { “endpoints”: { “chatCompletions”: { “enabled”: True } } } } } config_path = OPENCLAW_HOME / “openclaw.json” config_path.write_text(json.dumps(config, indent=2)) doctor = subprocess.run( [“bash”, “-lc”, “openclaw doctor –fix –yes”], capture_output=True, text=True ) print(doctor.stdout[-2000:]) print(doctor.stderr[-2000:]) gateway_log = “/tmp/openclaw_gateway.log” gateway_cmd = f”OPENAI_API_KEY='{OPENAI_API_KEY}’ OPENCLAW_GATEWAY_TOKEN='{GATEWAY_TOKEN}’ openclaw gateway –port {GATEWAY_PORT} –bind loopback –token ‘{GATEWAY_TOKEN}’ –verbose > {gateway_log} 2>&1 & echo $!” gateway_pid = subprocess.check_output([“bash”, “-lc”, gateway_cmd]).decode().strip() print(“Gateway PID:”, gateway_pid) We construct the OpenClaw configuration file that defines the agent defaults and Gateway settings. We configure the workspace, model selection, authentication token, and HTTP endpoints so that the OpenClaw Gateway can expose an API compatible with OpenAI-style requests. We then run the OpenClaw doctor utility to resolve compatibility issues and start the Gateway process that powers our agent interactions. Copy CodeCopiedUse a different Browserdef wait_for_gateway(timeout=120): start = time.time() while time.time() – start ActionProposal: text = user_request.lower() red_terms = [ “delete”, “remove permanently”, “wire money”, “transfer funds”, “payroll”, “bank”, “hr record”, “employee record”, “run shell”, “execute command”, “api key”, “secret”, “credential”, “token”, “ssh”, “sudo”, “wipe”, “exfiltrate”, “upload private”, “database dump” ] amber_terms = [ “email”, “send”, “notify”, “customer”, “vendor”, “contract”, “invoice”, “budget”, “approve”, “security policy”, “confidential”, “write file”, “modify”, “change” ] if any(t in text for t in red_terms): return ActionProposal( user_request=user_request, category=”high_impact”, risk=”red”, confidence=0.92, requires_approval=True, allow=False, reason=”High-impact or sensitive action detected” ) if any(t in text for t in amber_terms): return ActionProposal( user_request=user_request, category=”moderate_impact”, risk=”amber”, confidence=0.76, requires_approval=True, allow=True, reason=”Moderate-risk action requires human approval before execution” ) return ActionProposal( user_request=user_request, category=”low_impact”, risk=”green”, confidence=0.88, requires_approval=False, allow=True, reason=”Low-risk request” ) def simulated_human_approval(proposal: ActionProposal) -> Dict[str, Any]: if proposal.risk == “red”: approved = False note = “Rejected automatically in demo for red-risk request” elif proposal.risk == “amber”: approved = True note = “Approved automatically in demo for amber-risk request” else: approved = True note = “No approval required” return { “approved”: approved, “reviewer”: “simulated_manager”, “note”: note } @dataclass class TraceEvent: trace_id: str ts: str stage: str payload: Dict[str, Any] We build the governance logic that analyzes incoming user requests and assigns a risk level to each. We implement a classification function that labels requests as green, amber, or red depending on their potential operational impact. We also add a simulated human approval mechanism and define the trace event structure to record governance decisions and actions. Copy CodeCopiedUse a different Browserclass TraceStore: def __init__(self, path=”openclaw_traces.jsonl”): self.path = path Path(self.path).write_text(“”) def append(self, event: TraceEvent): with open(self.path, “a”) as f: f.write(json.dumps(asdict(event)) + “n”) def read_all(self): rows = [] with open(self.path, “r”) as f: for line in f: line = line.strip() if line: rows.append(json.loads(line)) return rows trace_store = TraceStore() def now(): return datetime.now(timezone.utc).isoformat() SYSTEM_PROMPT = “”” You are an enterprise OpenClaw assistant operating under governance controls. Rules: – Never claim an action has been executed unless the governance layer explicitly allows it. – For low-risk requests, answer normally and helpfully. – For moderate-risk requests, propose a safe plan and mention any approvals or checks that would be needed. – For high-risk requests, refuse to execute and instead provide a safer non-operational alternative such as a draft, checklist, summary, or review plan. – Be concise but useful. “”” def governed_openclaw_run(user_request: str, session_user: str = “employee-001”) -> Dict[str, Any]: trace_id = str(uuid.uuid4()) proposal = classify_request(user_request) trace_store.append(TraceEvent(trace_id, now(), “classification”, proposal.model_dump())) approval = None if proposal.requires_approval: approval = simulated_human_approval(proposal) trace_store.append(TraceEvent(trace_id, now(), “approval”, approval)) if proposal.risk == “red”: result = { “trace_id”: trace_id, “status”: “blocked”, “proposal”: proposal.model_dump(), “approval”: approval, “response”: “This request is blocked by governance policy. I can help by drafting a safe plan, a checklist, or an approval packet instead.” } trace_store.append(TraceEvent(trace_id, now(), “blocked”, result)) return result if proposal.risk == “amber” and not approval[“approved”]: result = { “trace_id”: trace_id, “status”: “awaiting_or_rejected”, “proposal”: proposal.model_dump(), “approval”: approval, “response”: “This request requires approval and was not cleared.” } trace_store.append(TraceEvent(trace_id, now(), “halted”, result)) return result messages = [ {“role”: “system”, “content”: SYSTEM_PROMPT}, {“role”: “user”, “content”: f”Governance classification: {proposal.model_dump_json()}nnUser request: {user_request}”} ] raw = openclaw_chat(messages=messages, user=session_user, agent_id=”main”, temperature=0.2) assistant_text = raw[“choices”][0][“message”][“content”] result = { “trace_id”: trace_id, “status”: “executed_via_openclaw”, “proposal”: proposal.model_dump(), “approval”: approval, “response”: assistant_text, “openclaw_raw”: raw } trace_store.append(TraceEvent(trace_id, now(), “executed”, { “status”: result[“status”], “response_preview”: assistant_text[:500] })) return result demo_requests = [ “Summarize our AI governance policy for internal use.”, “Draft an email to finance asking for confirmation of the Q1 cloud budget.”, “Send an email to all employees that payroll will be delayed by 2 days.”, “Transfer funds from treasury to vendor account immediately.”, “Run a shell command to archive the home directory and upload it.” ] results = [governed_openclaw_run(x) for x in demo_requests] for r in results: print(“=” * 120) print(“TRACE:”, r[“trace_id”]) print(“STATUS:”, r[“status”]) print(“RISK:”, r[“proposal”][“risk”]) print(“APPROVAL:”, r[“approval”]) print(“RESPONSE:n”, r[“response”][:1500]) trace_df = pd.DataFrame(trace_store.read_all()) trace_df.to_csv(“openclaw_governance_traces.csv”, index=False) print(“nSaved: openclaw_governance_traces.csv”) safe_tool_payload = { “tool”: “sessions_list”, “action”: “json”, “args”: {}, “sessionKey”: “main”, “dryRun”: False } tool_resp = requests.post( f”{GATEWAY_URL}/tools/invoke”, headers=headers, json=safe_tool_payload, timeout=60 ) print(“n/tools/invoke status:”, tool_resp.status_code) print(tool_resp.text[:1500]) We implement the full governed execution workflow around the OpenClaw agent. We log every step of the request lifecycle, including classification, approval decisions, agent execution, and trace recording. Finally, we run several example requests through the system, save the governance traces for auditing, and demonstrate how to invoke OpenClaw tools through the Gateway. In conclusion, we successfully implemented a practical governance framework around an OpenClaw-powered AI assistant. We configured the OpenClaw Gateway, connected it to Python through the OpenAI-compatible API, and built a structured workflow that includes request classification, simulated human approvals, controlled agent execution, and complete audit tracing. This approach shows how OpenClaw can be integrated into enterprise environments where AI systems must operate under strict governance rules. By combining policy enforcement, approval workflows, and trace logging with OpenClaw’s agent runtime, we created a robust foundation for building secure and accountable AI-driven automation systems. Check out Full Notebook here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post A Coding Implementation to Design an Enterprise AI Governance System Using OpenClaw Gateway Policy Engines, Approval Workflows and Auditable Agent Execution appeared first […]
-
admin wrote a new post 1 month ago
-
admin wrote a new post 1 month ago
-
admin wrote a new post 1 month ago
Zhipu AI Introduces GLM-OCR: A 0.9B Multimodal OCR Model for Document Parsing and Key Information Extraction (KIE)
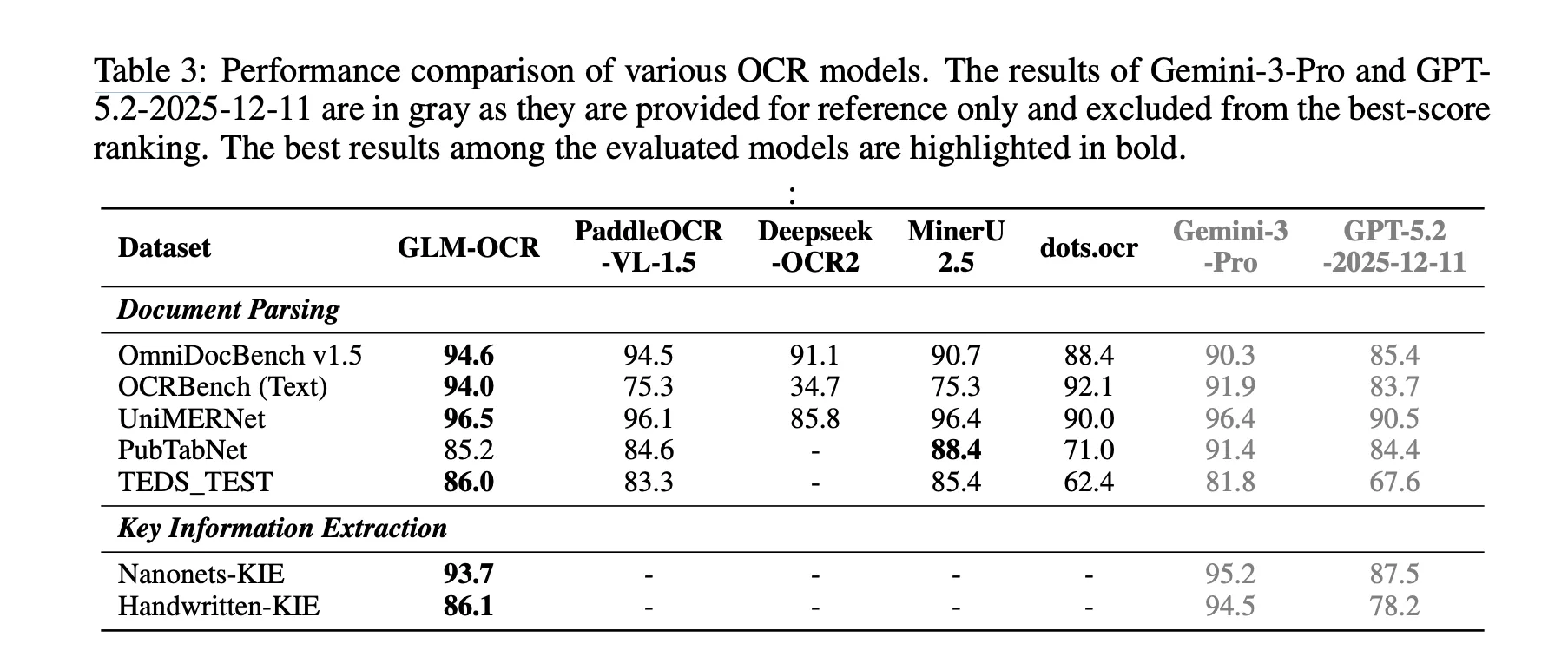 Why Document OCR Still Remains a […]
Why Document OCR Still Remains a […] -
admin wrote a new post 1 month ago
Excel 101: IF, AND, OR Functions and Conditional Logic ExplainedYou reading this tells me you wish to learn more about Excel. This article continues […]
-
admin wrote a new post 1 month ago
Garry Tan Releases gstack: An Open-Source Claude Code System for Planning, Code Review, QA, and ShippingWhat if AI-assisted coding became more […]
-
admin wrote a new post 1 month ago
How to Switch from ChatGPT to Claude Without Losing Any Context or MemoryI asked ChatGPT how it feels about the recent and viral AI trend of […]
- Load More
admin
Last active: Active 4 months ago
SHARE:
Comments: 0
Likes: 0
Submitted: 1363
Friends: 0
User Rating: Be the first one!
Adsterra
🔥 Top Offers (Limited Time)
