-
admin wrote a new post 3 weeks, 6 days ago
What is Elasticsearch?Suppose you want to locate a particular piece of information in a library that is the size of a city. This is a predicament […]
-
admin wrote a new post 3 weeks, 6 days ago
I Built a Smart Movie Recommender with Collaborative FilteringRecommendation systems are the invisible engines that can personalize our social […]
-
admin wrote a new post 3 weeks, 6 days ago
How to Build a Self-Organizing Agent Memory System for Long-Term AI Reasoning In this tutorial, we build a self-organizing memory system for an […]
-
admin wrote a new post 4 weeks ago
-
admin wrote a new post 4 weeks ago
[In-Depth Guide] The Complete CTGAN + SDV Pipeline for High-Fidelity Synthetic DataIn this tutorial, we build a complete, production-grade synthetic […]
-
admin wrote a new post 4 weeks ago
The Content Gap: What Creators Are (Still) Not Saying About Race, Class, and Capital57% of Gen Z want to be creators. Those are bleak numbers for the traditional choices of firefighter and astronaut, as we saw in the past….
-
admin wrote a new post 4 weeks ago
ALS stole this musician’s voice. AI let him sing again.
There are tears in the audience as Patrick Darling’s song begins to play. It’s a hea […]
-
admin wrote a new post 4 weeks ago
The Download: an exclusive chat with Jim O’Neill, and the surprising truth about heists
 This is today’s edition of The Download, our weekday new […]
This is today’s edition of The Download, our weekday new […] -
admin wrote a new post 4 weeks ago
GPT-5.2 derives a new result in theoretical physicsA new preprint shows GPT-5.2 proposing a new formula for a gluon amplitude, later formally proved and verified by OpenAI and academic collaborators.
-
admin wrote a new post 4 weeks ago
Introducing Lockdown Mode and Elevated Risk labels in ChatGPTIntroducing Lockdown Mode and Elevated Risk labels in ChatGPT to help organizations defend against prompt injection and AI-driven data exfiltration.
-
admin wrote a new post 4 weeks, 1 day ago
What is Prompt Chaining?You type in a lengthy prompt, well over 500 words, or even 1000 words. It structures everything perfectly. Explains in […]
-
admin wrote a new post 4 weeks, 1 day ago
I Built an AI Agent that Predicts Match Winners in the ICC Men’s T20 World Cup 2026The T20 World Cup 2026 brings exciting matches, and fans […]
-
admin wrote a new post 4 weeks, 1 day ago
-
admin wrote a new post 4 weeks, 1 day ago
-
admin wrote a new post 4 weeks, 1 day ago
The myth of the high-tech heistMaking a movie is a lot like pulling off a heist. That’s what Steven Soderbergh—director of the Ocean’s franc […]
-
admin wrote a new post 4 weeks, 1 day ago
-
admin wrote a new post 4 weeks, 1 day ago
Guide to Build a Data Analysis & Visualization Agent Using Swarm Architecture Swarm architecture brings together specialized AI agents that […]
-
admin wrote a new post 4 weeks, 1 day ago
How Andrej Karpathy Built a Working Transformer in 243 Lines of CodeThe AI researcher Andrej Karpathy has developed an educational tool microGPT […]
-
admin wrote a new post 4 weeks, 1 day ago
OpenAI Releases a Research Preview of GPT‑5.3-Codex-Spark: A 15x Faster AI Coding Model Delivering Over 1000 Tokens Per Second on Cerebras Hardware
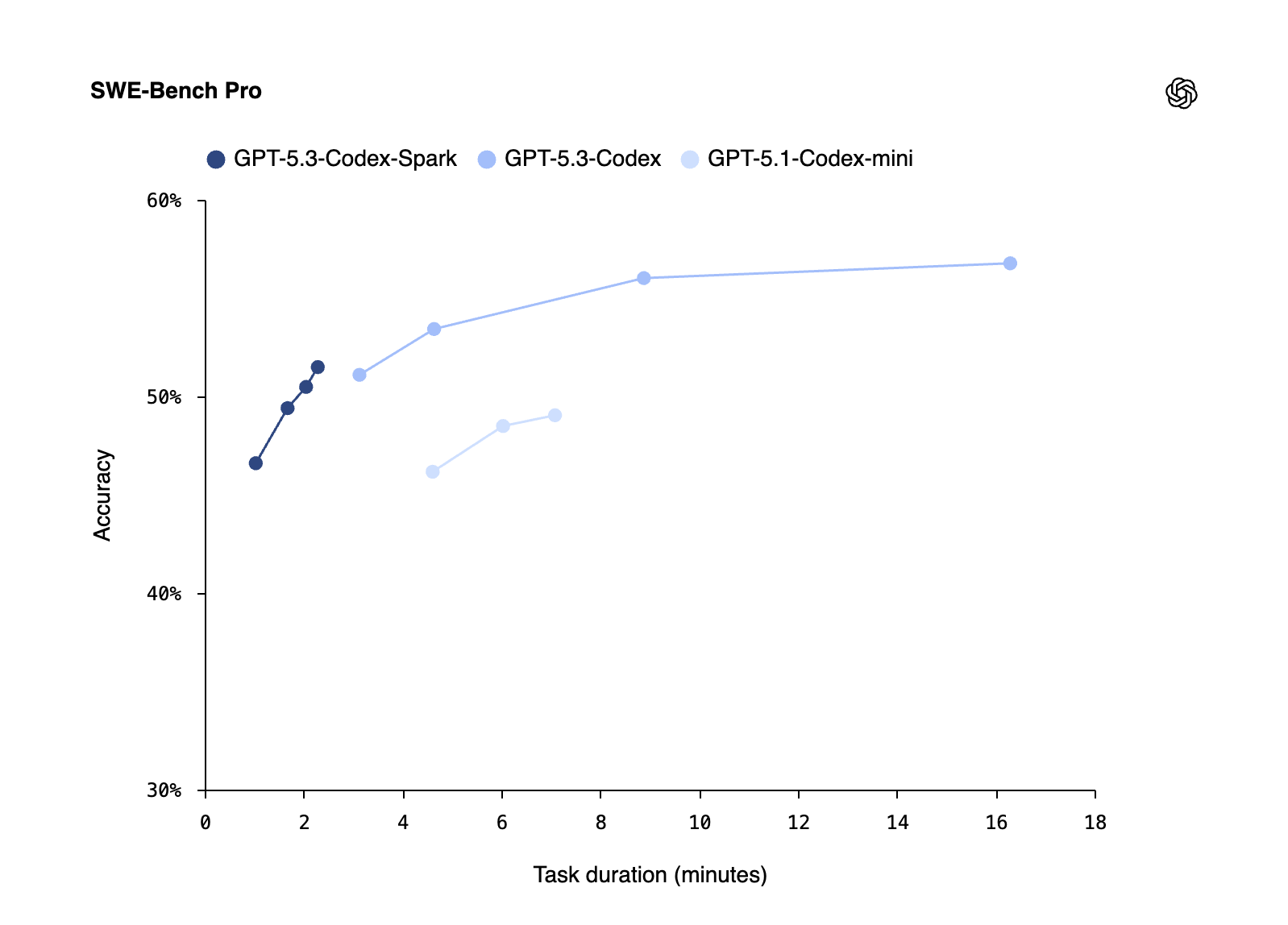 OpenAI just launched a new research preview called GPT-5.3 Codex-Spark. This model is built for 1 thing: extreme speed. While the standard GPT-5.3 Codex focuses on deep reasoning, Spark is designed for near-instant response times. It is the result of a deep hardware-software integration between OpenAI and Cerebras. The results are game-changing. Spark is 15x faster than the flagship GPT-5.3 Codex. It consistently delivers over 1000 tokens per second. This speed effectively removes the delay between a developer’s thought and the model’s code output. The Hardware: Wafer-Scale Engineering The massive performance jump is powered by the Cerebras Wafer-Scale Engine 3 (WSE-3). Traditional AI models run on clusters of small GPUs. These GPUs must communicate to each other over cables, which creates a ‘bottleneck.’ This bottleneck slows down the speed of the model. The WSE-3 is different. It is a single, giant chip the size of a whole silicon wafer. Because the entire model lives on 1 piece of silicon, there are no cables to slow it down. This architecture provides: Massive on-chip memory. Ultra-high bandwidth. Low-latency compute. By using the Cerebras CS-3 system, OpenAI can run inference at speeds that traditional GPU clusters cannot reach. Software Optimizations and Low Latency Speed is not just about the chip. OpenAI re-engineered the way the model communicates with your computer. They moved away from traditional request methods and introduced a persistent WebSocket connection. This change leads to several technical improvements: Round-Trip Time (RTT): Client-server overhead is reduced by 80%. Time-to-First-Token (TTFT): This is improved by 50%, meaning the code starts appearing almost the moment you hit enter. Per-Token Overhead: Internal processing time per token is cut by 30%. These optimizations allow for ‘Real-Time Steering.’ You can interrupt the model while it is typing and redirect its logic without waiting for the full block to finish. The Trade-offs: Speed vs. Reasoning GPT-5.3 Codex-Spark is optimized for throughput, not deep complexity. It is a ‘smaller’ model than the flagship GPT-5.3 Codex. Because of this, it has lower reasoning depth. Devs should be aware of these performance differences: Benchmarks: Spark scores lower on SWE-Bench Pro and Terminal-Bench 2.0 compared to the flagship model. It may struggle with very complex, multi-file architecture changes. Security: Under OpenAI’s Preparedness Framework, the flagship GPT-5.3 Codex is rated as ‘High’ capability for cybersecurity. Spark does not meet this high threshold. It should not be used for sensitive security logic or autonomous authentication tasks. Quick Specs and Access Spark is available now for ChatGPT Pro users and developers. You can access it through the following tools: Codex App: Use the model picker to select ‘Spark.’ VS Code Extension: Integrated directly into the composer. CLI: Access it via the command codex –model gpt-5.3-codex-spark. FeatureGPT-5.3 Codex-SparkGPT-5.3 Codex (Flagship)Tokens per Second1000+~70Context Window128k128kHardwareCerebras WSE-3NVIDIA GPU ClustersBest ForFast IterationDeep Reasoning / Security Key Takeaways Great Speed: Spark is 15x faster than the flagship GPT-5.3 Codex, delivering an unprecedented throughput of over 1,000 tokens per second to enable near-instant code generation. Custom Silicon Infrastructure: This is OpenAI’s first model to run on Cerebras Wafer-Scale Engine 3 (WSE-3) hardware rather than traditional NVIDIA GPUs, using ‘wafer-scale’ memory to eliminate data bottlenecks. Drastic Latency Reduction: The integration of a persistent WebSocket connection reduces client-server round-trip overhead by 80% and improves the time-to-first-token by 50%. Real-Time Steering: Designed for ‘micro-iterations,’ the model’s speed allows developers to interrupt and redirect logic in real-time, shifting the workflow from batch-processing to live pair-programming. Targeted Capability Trade-offs: While faster, Spark has lower reasoning depth than the flagship model and does not meet the ‘High capability’ threshold for cybersecurity in OpenAI’s Preparedness Framework, making it unsuitable for sensitive auth or security tasks. Check out the Technical details here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post OpenAI Releases a Research Preview of GPT‑5.3-Codex-Spark: A 15x Faster AI Coding Model Delivering Over 1000 Tokens Per Second on Cerebras Hardware appeared first on […]
OpenAI just launched a new research preview called GPT-5.3 Codex-Spark. This model is built for 1 thing: extreme speed. While the standard GPT-5.3 Codex focuses on deep reasoning, Spark is designed for near-instant response times. It is the result of a deep hardware-software integration between OpenAI and Cerebras. The results are game-changing. Spark is 15x faster than the flagship GPT-5.3 Codex. It consistently delivers over 1000 tokens per second. This speed effectively removes the delay between a developer’s thought and the model’s code output. The Hardware: Wafer-Scale Engineering The massive performance jump is powered by the Cerebras Wafer-Scale Engine 3 (WSE-3). Traditional AI models run on clusters of small GPUs. These GPUs must communicate to each other over cables, which creates a ‘bottleneck.’ This bottleneck slows down the speed of the model. The WSE-3 is different. It is a single, giant chip the size of a whole silicon wafer. Because the entire model lives on 1 piece of silicon, there are no cables to slow it down. This architecture provides: Massive on-chip memory. Ultra-high bandwidth. Low-latency compute. By using the Cerebras CS-3 system, OpenAI can run inference at speeds that traditional GPU clusters cannot reach. Software Optimizations and Low Latency Speed is not just about the chip. OpenAI re-engineered the way the model communicates with your computer. They moved away from traditional request methods and introduced a persistent WebSocket connection. This change leads to several technical improvements: Round-Trip Time (RTT): Client-server overhead is reduced by 80%. Time-to-First-Token (TTFT): This is improved by 50%, meaning the code starts appearing almost the moment you hit enter. Per-Token Overhead: Internal processing time per token is cut by 30%. These optimizations allow for ‘Real-Time Steering.’ You can interrupt the model while it is typing and redirect its logic without waiting for the full block to finish. The Trade-offs: Speed vs. Reasoning GPT-5.3 Codex-Spark is optimized for throughput, not deep complexity. It is a ‘smaller’ model than the flagship GPT-5.3 Codex. Because of this, it has lower reasoning depth. Devs should be aware of these performance differences: Benchmarks: Spark scores lower on SWE-Bench Pro and Terminal-Bench 2.0 compared to the flagship model. It may struggle with very complex, multi-file architecture changes. Security: Under OpenAI’s Preparedness Framework, the flagship GPT-5.3 Codex is rated as ‘High’ capability for cybersecurity. Spark does not meet this high threshold. It should not be used for sensitive security logic or autonomous authentication tasks. Quick Specs and Access Spark is available now for ChatGPT Pro users and developers. You can access it through the following tools: Codex App: Use the model picker to select ‘Spark.’ VS Code Extension: Integrated directly into the composer. CLI: Access it via the command codex –model gpt-5.3-codex-spark. FeatureGPT-5.3 Codex-SparkGPT-5.3 Codex (Flagship)Tokens per Second1000+~70Context Window128k128kHardwareCerebras WSE-3NVIDIA GPU ClustersBest ForFast IterationDeep Reasoning / Security Key Takeaways Great Speed: Spark is 15x faster than the flagship GPT-5.3 Codex, delivering an unprecedented throughput of over 1,000 tokens per second to enable near-instant code generation. Custom Silicon Infrastructure: This is OpenAI’s first model to run on Cerebras Wafer-Scale Engine 3 (WSE-3) hardware rather than traditional NVIDIA GPUs, using ‘wafer-scale’ memory to eliminate data bottlenecks. Drastic Latency Reduction: The integration of a persistent WebSocket connection reduces client-server round-trip overhead by 80% and improves the time-to-first-token by 50%. Real-Time Steering: Designed for ‘micro-iterations,’ the model’s speed allows developers to interrupt and redirect logic in real-time, shifting the workflow from batch-processing to live pair-programming. Targeted Capability Trade-offs: While faster, Spark has lower reasoning depth than the flagship model and does not meet the ‘High capability’ threshold for cybersecurity in OpenAI’s Preparedness Framework, making it unsuitable for sensitive auth or security tasks. Check out the Technical details here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post OpenAI Releases a Research Preview of GPT‑5.3-Codex-Spark: A 15x Faster AI Coding Model Delivering Over 1000 Tokens Per Second on Cerebras Hardware appeared first on […] -
admin wrote a new post 4 weeks, 1 day ago
Is This AGI? Google’s Gemini 3 Deep Think Shatters Humanity’s Last Exam And Hits 84.6% On ARC-AGI-2 Performance Today
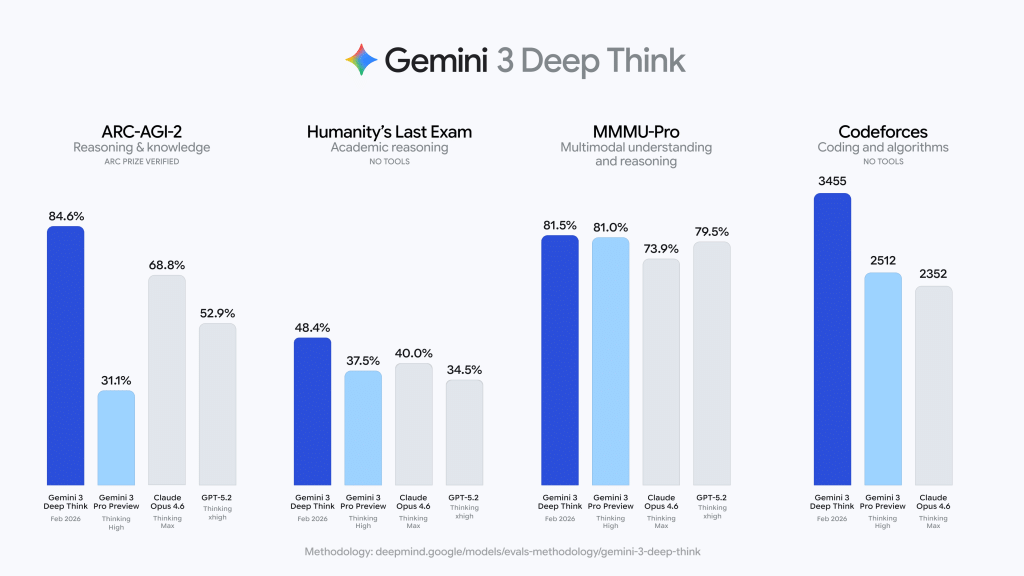 Google announced a major update […]
Google announced a major update […] - Load More
admin
Last active: Active 3 months ago
Comments: 0
Likes: 0
Submitted: 1046
Friends: 0
User Rating: Be the first one!