
-
admin wrote a new post 4 hours, 51 minutes ago
GLM-5.1: Architecture, Benchmarks, Capabilities & How to Use ItZ.ai is out with its next-generation flagship AI model and has named it GLM-5.1. With […]
-
admin wrote a new post 4 hours, 51 minutes ago
-
admin wrote a new post 4 hours, 57 minutes ago
Liquid AI Releases LFM2.5-VL-450M: a 450M-Parameter Vision-Language Model with Bounding Box Prediction, Multilingual Support, and Sub-250ms Edge Inference
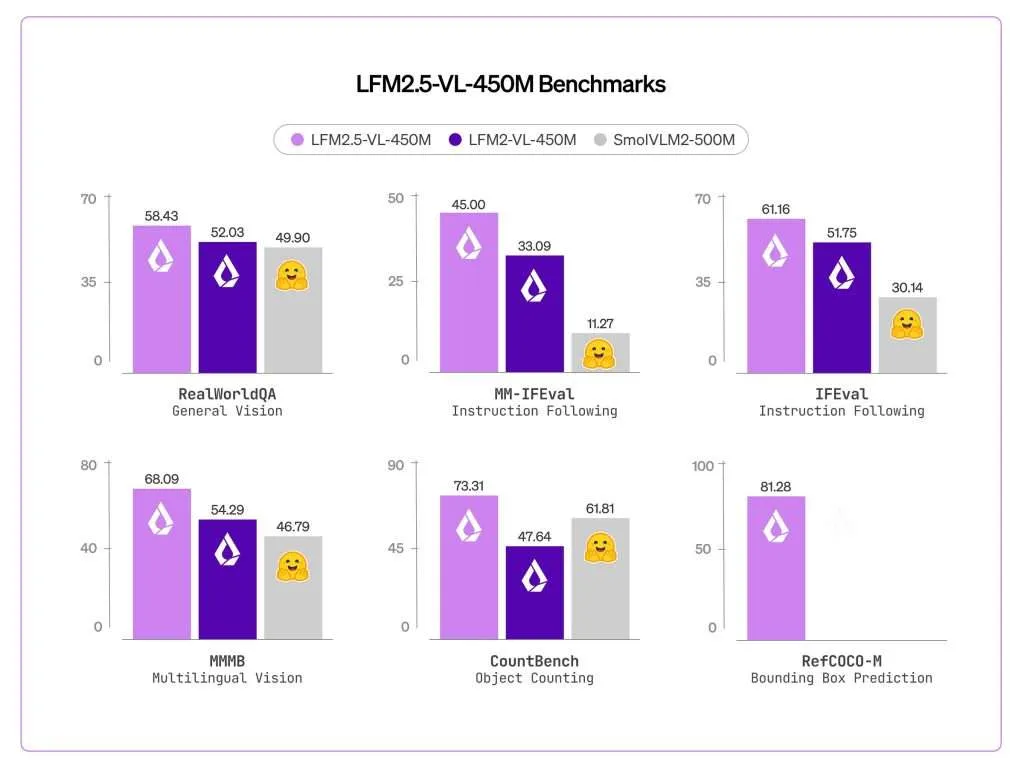 Liquid AI just released LFM2.5-VL-450M, an updated version of its earlier LFM2-VL-450M vision-language model. The new release introduces bounding box prediction, improved instruction following, expanded multilingual understanding, and function calling support — all within a 450M-parameter footprint designed to run directly on edge hardware ranging from embedded AI modules like NVIDIA Jetson Orin, to mini-PC APUs like AMD Ryzen AI Max+ 395, to flagship phone SoCs like the Snapdragon 8 Elite inside the Samsung S25 Ultra. What is a Vision-Language Model and Why Model Size Matters Before going deeper, it helps to understand what a vision-language model (VLM) is. A VLM is a model that can process both images and text together — you can send it a photo and ask questions about it in natural language, and it will respond. Most large VLMs require substantial GPU memory and cloud infrastructure to run. That’s a problem for real-world deployment scenarios like warehouse robots, smart glasses, or retail shelf cameras, where compute is limited and latency must be low. LFM2.5-VL-450M is Liquid AI’s answer to this constraint: a model small enough to fit on edge hardware while still supporting a meaningful set of vision and language capabilities. Architecture and Training LFM2.5-VL-450M uses LFM2.5-350M as its language model backbone and SigLIP2 NaFlex shape-optimized 86M as its vision encoder. The context window is 32,768 tokens with a vocabulary size of 65,536. For image handling, the model supports native resolution processing up to 512×512 pixels without upscaling, preserves non-standard aspect ratios without distortion, and uses a tiling strategy that splits large images into non-overlapping 512×512 patches while including thumbnail encoding for global context. The thumbnail encoding is important: without it, tiling would give the model only local patches with no sense of the overall scene. At inference time, users can tune the maximum image tokens and tile count for a speed/quality tradeoff without retraining, which is useful when deploying across hardware with different compute budgets. The recommended generation parameters from Liquid AI are temperature=0.1, min_p=0.15, and repetition_penalty=1.05 for text, and min_image_tokens=32, max_image_tokens=256, and do_image_splitting=True for vision inputs. On the training side, Liquid AI scaled pre-training from 10T to 28T tokens compared to LFM2-VL-450M, followed by post-training using preference optimization and reinforcement learning to improve grounding, instruction following, and overall reliability across vision-language tasks. New Capabilities Over LFM2-VL-450M The most significant addition is bounding box prediction. LFM2.5-VL-450M scored 81.28 on RefCOCO-M, up from zero on the previous model. RefCOCO-M is a visual grounding benchmark that measures how accurately a model can locate an object in an image given a natural language description. In practice, the model outputs structured JSON with normalized coordinates identifying where objects are in a scene — not just describing what is there, but also locating it. This is meaningfully different from pure image captioning and makes the model directly usable in pipelines that need spatial outputs. Multilingual support also improved substantially. MMMB scores improved from 54.29 to 68.09, covering Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish. This is relevant for global deployments where local-language prompts must be understood alongside visual inputs, without needing separate localization pipelines. Instruction following improved as well. MM-IFEval scores went from 32.93 to 45.00, meaning the model more reliably adheres to explicit constraints given in a prompt — for example, responding in a particular format or restricting output to specific fields. Function calling support for text-only input was also added, measured by BFCLv4 at 21.08, a capability the previous model did not include. Function calling allows the model to be used in agentic pipelines where it needs to invoke external tools — for instance, calling a weather API or triggering an action in a downstream system. Benchmark Performance Across vision benchmarks evaluated using VLMEvalKit, LFM2.5-VL-450M outperforms both LFM2-VL-450M and SmolVLM2-500M on most tasks. Notable scores include 86.93 on POPE, 684 on OCRBench, 60.91 on MMBench (dev en), and 58.43 on RealWorldQA. Two benchmark gains stand out beyond the headline numbers. MMVet — which tests more open-ended visual understanding — improved from 33.85 to 41.10, a substantial relative gain. CountBench, which evaluates the model’s ability to count objects in a scene, improved from 47.64 to 73.31, one of the largest relative improvements in the table. InfoVQA held roughly flat at 43.02 versus 44.56 on the prior model. On language-only benchmarks, IFEval improved from 51.75 to 61.16 and Multi-IF from 26.21 to 34.63. The model does not outperform on all tasks — MMMU (val) dropped slightly from 34.44 to 32.67 — and Liquid AI notes the model is not well-suited for knowledge-intensive tasks or fine-grained OCR. Edge Inference Performance LFM2.5-VL-450M with Q4_0 quantization runs across the full range of target hardware, from embedded AI modules like Jetson Orin to mini-PC APUs like Ryzen AI Max+ 395 to flagship phone SoCs like Snapdragon 8 Elite. The latency numbers tell a clear story. On Jetson Orin, the model processes a 256×256 image in 233ms and a 512×512 image in 242ms — staying well under 250ms at both resolutions. This makes it fast enough to process every frame in a 4 FPS video stream with full vision-language understanding, not just detection. On Samsung S25 Ultra, latency is 950ms for 256×256 and 2.4 seconds for 512×512. On AMD Ryzen AI Max+ 395, it is 637ms for 256×256 and 944ms for 512×512 — under one second for the smaller resolution on both consumer devices, which keeps interactive applications responsive. Real-World Use Cases LFM2.5-VL-450M is especially well suited to real-world deployments where low latency, compact structured outputs, and efficient semantic reasoning matter most, including settings where offline operation or on-device processing is important for privacy. In industrial automation, compute-constrained environments such as passenger vehicles, agricultural machinery, and warehouses often limit perception models to bounding-box outputs. LFM2.5-VL-450M goes further, providing grounded scene understanding in a single pass — enabling richer outputs for settings like warehouse aisles, including worker actions, forklift movement, and inventory flow — while still fitting existing edge hardware like a Jetson Orin. For wearables and always-on monitoring, devices such as smart glasses, body-worn assistants, dashcams, and security or industrial monitors cannot afford large perception stacks or constant cloud streaming. An efficient VLM can produce compact semantic outputs locally, turning raw video into useful structured understanding while keeping compute demands low and preserving privacy. In retail and e-commerce, tasks like catalog ingestion, visual search, product matching, and shelf compliance require more than object detection, but richer visual understanding is often too expensive to deploy at scale. LFM2.5-VL-450M makes structured visual reasoning practical for these workloads. Key Takeaways LFM2.5-VL-450M adds bounding box prediction for the first time, scoring 81.28 on RefCOCO-M versus zero on the previous model, enabling the model to output structured spatial coordinates for detected objects — not just describe what it sees. Pre-training was scaled from 10T to 28T tokens, combined with post-training via preference optimization and reinforcement learning, driving consistent benchmark gains across vision and language tasks over LFM2-VL-450M. The model runs on edge hardware with sub-250ms latency, processing a 512×512 image in 242ms on NVIDIA Jetson Orin with Q4_0 quantization — fast enough for full vision-language understanding on every frame of a 4 FPS video stream without cloud offloading. Multilingual visual understanding improved significantly, with MMMB scores rising from 54.29 to 68.09 across Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish, making the model viable for global deployments without separate localization models. Check out the Technical details and Model Weight. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us The post Liquid AI Releases LFM2.5-VL-450M: a 450M-Parameter Vision-Language Model with Bounding Box Prediction, Multilingual Support, and Sub-250ms Edge Inference appeared first on M […]
Liquid AI just released LFM2.5-VL-450M, an updated version of its earlier LFM2-VL-450M vision-language model. The new release introduces bounding box prediction, improved instruction following, expanded multilingual understanding, and function calling support — all within a 450M-parameter footprint designed to run directly on edge hardware ranging from embedded AI modules like NVIDIA Jetson Orin, to mini-PC APUs like AMD Ryzen AI Max+ 395, to flagship phone SoCs like the Snapdragon 8 Elite inside the Samsung S25 Ultra. What is a Vision-Language Model and Why Model Size Matters Before going deeper, it helps to understand what a vision-language model (VLM) is. A VLM is a model that can process both images and text together — you can send it a photo and ask questions about it in natural language, and it will respond. Most large VLMs require substantial GPU memory and cloud infrastructure to run. That’s a problem for real-world deployment scenarios like warehouse robots, smart glasses, or retail shelf cameras, where compute is limited and latency must be low. LFM2.5-VL-450M is Liquid AI’s answer to this constraint: a model small enough to fit on edge hardware while still supporting a meaningful set of vision and language capabilities. Architecture and Training LFM2.5-VL-450M uses LFM2.5-350M as its language model backbone and SigLIP2 NaFlex shape-optimized 86M as its vision encoder. The context window is 32,768 tokens with a vocabulary size of 65,536. For image handling, the model supports native resolution processing up to 512×512 pixels without upscaling, preserves non-standard aspect ratios without distortion, and uses a tiling strategy that splits large images into non-overlapping 512×512 patches while including thumbnail encoding for global context. The thumbnail encoding is important: without it, tiling would give the model only local patches with no sense of the overall scene. At inference time, users can tune the maximum image tokens and tile count for a speed/quality tradeoff without retraining, which is useful when deploying across hardware with different compute budgets. The recommended generation parameters from Liquid AI are temperature=0.1, min_p=0.15, and repetition_penalty=1.05 for text, and min_image_tokens=32, max_image_tokens=256, and do_image_splitting=True for vision inputs. On the training side, Liquid AI scaled pre-training from 10T to 28T tokens compared to LFM2-VL-450M, followed by post-training using preference optimization and reinforcement learning to improve grounding, instruction following, and overall reliability across vision-language tasks. New Capabilities Over LFM2-VL-450M The most significant addition is bounding box prediction. LFM2.5-VL-450M scored 81.28 on RefCOCO-M, up from zero on the previous model. RefCOCO-M is a visual grounding benchmark that measures how accurately a model can locate an object in an image given a natural language description. In practice, the model outputs structured JSON with normalized coordinates identifying where objects are in a scene — not just describing what is there, but also locating it. This is meaningfully different from pure image captioning and makes the model directly usable in pipelines that need spatial outputs. Multilingual support also improved substantially. MMMB scores improved from 54.29 to 68.09, covering Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish. This is relevant for global deployments where local-language prompts must be understood alongside visual inputs, without needing separate localization pipelines. Instruction following improved as well. MM-IFEval scores went from 32.93 to 45.00, meaning the model more reliably adheres to explicit constraints given in a prompt — for example, responding in a particular format or restricting output to specific fields. Function calling support for text-only input was also added, measured by BFCLv4 at 21.08, a capability the previous model did not include. Function calling allows the model to be used in agentic pipelines where it needs to invoke external tools — for instance, calling a weather API or triggering an action in a downstream system. Benchmark Performance Across vision benchmarks evaluated using VLMEvalKit, LFM2.5-VL-450M outperforms both LFM2-VL-450M and SmolVLM2-500M on most tasks. Notable scores include 86.93 on POPE, 684 on OCRBench, 60.91 on MMBench (dev en), and 58.43 on RealWorldQA. Two benchmark gains stand out beyond the headline numbers. MMVet — which tests more open-ended visual understanding — improved from 33.85 to 41.10, a substantial relative gain. CountBench, which evaluates the model’s ability to count objects in a scene, improved from 47.64 to 73.31, one of the largest relative improvements in the table. InfoVQA held roughly flat at 43.02 versus 44.56 on the prior model. On language-only benchmarks, IFEval improved from 51.75 to 61.16 and Multi-IF from 26.21 to 34.63. The model does not outperform on all tasks — MMMU (val) dropped slightly from 34.44 to 32.67 — and Liquid AI notes the model is not well-suited for knowledge-intensive tasks or fine-grained OCR. Edge Inference Performance LFM2.5-VL-450M with Q4_0 quantization runs across the full range of target hardware, from embedded AI modules like Jetson Orin to mini-PC APUs like Ryzen AI Max+ 395 to flagship phone SoCs like Snapdragon 8 Elite. The latency numbers tell a clear story. On Jetson Orin, the model processes a 256×256 image in 233ms and a 512×512 image in 242ms — staying well under 250ms at both resolutions. This makes it fast enough to process every frame in a 4 FPS video stream with full vision-language understanding, not just detection. On Samsung S25 Ultra, latency is 950ms for 256×256 and 2.4 seconds for 512×512. On AMD Ryzen AI Max+ 395, it is 637ms for 256×256 and 944ms for 512×512 — under one second for the smaller resolution on both consumer devices, which keeps interactive applications responsive. Real-World Use Cases LFM2.5-VL-450M is especially well suited to real-world deployments where low latency, compact structured outputs, and efficient semantic reasoning matter most, including settings where offline operation or on-device processing is important for privacy. In industrial automation, compute-constrained environments such as passenger vehicles, agricultural machinery, and warehouses often limit perception models to bounding-box outputs. LFM2.5-VL-450M goes further, providing grounded scene understanding in a single pass — enabling richer outputs for settings like warehouse aisles, including worker actions, forklift movement, and inventory flow — while still fitting existing edge hardware like a Jetson Orin. For wearables and always-on monitoring, devices such as smart glasses, body-worn assistants, dashcams, and security or industrial monitors cannot afford large perception stacks or constant cloud streaming. An efficient VLM can produce compact semantic outputs locally, turning raw video into useful structured understanding while keeping compute demands low and preserving privacy. In retail and e-commerce, tasks like catalog ingestion, visual search, product matching, and shelf compliance require more than object detection, but richer visual understanding is often too expensive to deploy at scale. LFM2.5-VL-450M makes structured visual reasoning practical for these workloads. Key Takeaways LFM2.5-VL-450M adds bounding box prediction for the first time, scoring 81.28 on RefCOCO-M versus zero on the previous model, enabling the model to output structured spatial coordinates for detected objects — not just describe what it sees. Pre-training was scaled from 10T to 28T tokens, combined with post-training via preference optimization and reinforcement learning, driving consistent benchmark gains across vision and language tasks over LFM2-VL-450M. The model runs on edge hardware with sub-250ms latency, processing a 512×512 image in 242ms on NVIDIA Jetson Orin with Q4_0 quantization — fast enough for full vision-language understanding on every frame of a 4 FPS video stream without cloud offloading. Multilingual visual understanding improved significantly, with MMMB scores rising from 54.29 to 68.09 across Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish, making the model viable for global deployments without separate localization models. Check out the Technical details and Model Weight. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us The post Liquid AI Releases LFM2.5-VL-450M: a 450M-Parameter Vision-Language Model with Bounding Box Prediction, Multilingual Support, and Sub-250ms Edge Inference appeared first on M […] -
admin wrote a new post 16 hours, 58 minutes ago
Researchers from MIT, NVIDIA, and Zhejiang University Propose TriAttention: A KV Cache Compression Method That Matches Full Attention at 2.5× Higher Throughput
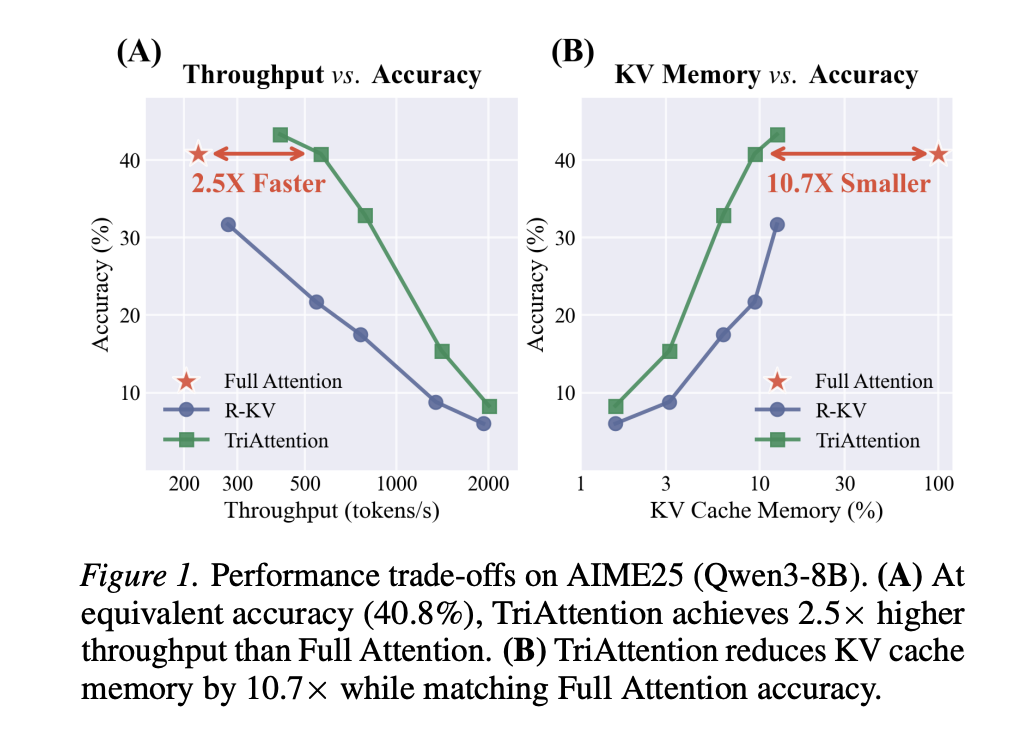 Long-chain reasoning is one of the most compute-intensive tasks in modern large language models. When a model like DeepSeek-R1 or Qwen3 works through a complex math problem, it can generate tens of thousands of tokens before arriving at an answer. Every one of those tokens must be stored in what is called the KV cache — a memory structure that holds the Key and Value vectors the model needs to attend back to during generation. The longer the reasoning chain, the larger the KV cache grows, and for many deployment scenarios, especially on consumer hardware, this growth eventually exhausts GPU memory entirely. A team of researchers from MIT, NVIDIA, and Zhejiang University proposed a method called TriAttention that directly addresses this problem. On the AIME25 mathematical reasoning benchmark with 32K-token generation, TriAttention matches Full Attention accuracy while achieving 2.5× higher throughput or 10.7× KV memory reduction. Leading baselines achieve only about half the accuracy at the same efficiency level. The Problem with Existing KV Cache Compression To understand why TriAttention is important, it helps to understand the standard approach to KV cache compression. Most existing methods — including SnapKV, H2O, and R-KV — work by estimating which tokens in the KV cache are important and evicting the rest. Importance is typically estimated by looking at attention scores: if a key receives high attention from recent queries, it is considered important and kept. The catch is that these methods operate in what the research team calls post-RoPE space. RoPE, or Rotary Position Embedding, is the positional encoding scheme used by most modern LLMs including Llama, Qwen, and Mistral. RoPE encodes position by rotating the Query and Key vectors in a frequency-dependent way. As a result, a query vector at position 10,000 looks very different from the same semantic query at position 100, because its direction has been rotated by the position encoding. This rotation means that only the most recently generated queries have orientations that are ‘up to date’ for estimating which keys are important right now. Prior work has confirmed this empirically: increasing the observation window for importance estimation does not help — performance peaks at around 25 queries and declines after that. With such a tiny window, some keys that will become important later get permanently evicted. This problem is especially acute for what the research team calls retrieval heads — attention heads whose function is to retrieve specific factual tokens from long contexts. The relevant tokens for a retrieval head can remain dormant for thousands of tokens before suddenly becoming essential to the reasoning chain. Post-RoPE methods, operating over a narrow observation window, see low attention on those tokens during the dormant period and permanently evict them. When the model later needs to recall that information, it is already gone, and the chain of thought breaks. The Pre-RoPE Observation: Q/K Concentration The key insight in TriAttention comes from looking at Query and Key vectors before RoPE rotation is applied — the pre-RoPE space. When the research team visualized Q and K vectors in this space, they found something consistent and striking: across the vast majority of attention heads and across multiple model architectures, both Q and K vectors cluster tightly around fixed, non-zero center points. The research team terms this property Q/K concentration, and measures it using the Mean Resultant Length R — a standard directional statistics measure where R → 1 means tight clustering and R → 0 means dispersion in all directions. On Qwen3-8B, approximately 90% of attention heads exhibit R > 0.95, meaning their pre-RoPE Q/K vectors are nearly perfectly concentrated around their respective centers. Critically, these centers are stable across different token positions and across different input sequences — they are an intrinsic property of the model’s learned weights, not a property of any particular input. The research team further confirm that Q/K concentration is domain-agnostic: measuring Mean Resultant Length across Math, Coding, and Chat domains on Qwen3-8B yields nearly identical values of 0.977–0.980. This stability is what post-RoPE methods cannot exploit. RoPE rotation disperses these concentrated vectors into arc patterns that vary with position. But in pre-RoPE space, the centers remain fixed. From Concentration to a Trigonometric Series The research team then show mathematically that when Q and K vectors are concentrated around their centers, the attention logit — the raw score before softmax that determines how much a query attends to a key — simplifies dramatically. Substituting the Q/K centers into the RoPE attention formula, the logit reduces to a function that depends only on the Q-K distance (the relative positional gap between query and key), expressed as a trigonometric series: logit(Δ)≈∑f‖q‾f‖‖k‾f‖⏟amplitudecos(ωfΔ+ϕ‾f⏟phase)=∑f[afcos(ωfΔ)+bfsin(ωfΔ)] text{logit}(Delta) approx sum_{f} underbrace{|bar{q}_f| |bar{k}_f|}_{text{amplitude}} cos(omega_f Delta + underbrace{bar{phi}_f}_{text{phase}}) = sum_{f} [a_f cos(omega_f Delta) + b_f sin(omega_f Delta)] Here, Δ is the positional distance, ωf are the RoPE rotation frequencies for each frequency band f, and the coefficients af and bf are determined by the Q/K centers. This series produces a characteristic attention-vs-distance curve for each head. Some heads prefer nearby keys (local attention), others prefer very distant keys (attention sinks). The centers, computed offline from calibration data, fully determine which distances are preferred. The research team validated this experimentally across 1,152 attention heads in Qwen3-8B and across Qwen2.5 and Llama3 architectures. The Pearson correlation between the predicted trigonometric curve and the actual attention logits has a mean above 0.5 across all heads, with many heads achieving correlations of 0.6–0.9. The research team further validates this on GLM-4.7-Flash, which uses Multi-head Latent Attention (MLA) rather than standard Grouped-Query Attention — a meaningfully different attention architecture. On MLA, 96.6% of heads exhibit R > 0.95, compared to 84.7% for GQA, confirming that Q/K concentration is not specific to one attention design but is a general property of modern LLMs. How TriAttention Uses This TriAttention is a KV cache compression method that uses these findings to score keys without needing any live query observations. The scoring function has two components: The Trigonometric Series Score (Strig) uses the Q center computed offline and the actual cached key representation to estimate how much attention the key will receive, based on its positional distance from future queries. Because a key may be attended to by queries at many future positions, TriAttention averages this score over a set of future offsets using geometric spacing. Strig(k,Δ)=∑f‖𝔼[qf]‖⋅‖kf‖⋅cos(ωfΔ+ϕf)S_{text{trig}}(k, Delta) = sum_{f} |mathbb{E}[q_f]| cdot |k_f| cdot cos(omega_f Delta + phi_f) The Norm-Based Score (Snorm) handles the minority of attention heads where Q/K concentration is lower. It weights each frequency band by the expected query norm contribution, providing complementary information about token salience beyond distance preference alone. Snorm(0)(k)=∑f𝔼[‖qf‖]⋅‖kf‖S_{text{norm}}^{(0)}(k) = sum_{f} mathbb{E}[|q_f|] cdot |k_f| The two scores are combined using the Mean Resultant Length R as an adaptive weight: when concentration is high, Strig dominates; when concentration is lower, Snorm contributes more. Every 128 generated tokens, TriAttention scores all keys in the cache and retains only the top-B, evicting the rest. Results on Mathematical Reasoning On AIME24 with Qwen3-8B, TriAttention achieves 42.1% accuracy against Full Attention’s 57.1%, while R-KV achieves only 25.4% at the same KV budget of 2,048 tokens. On AIME25, TriAttention achieves 32.9% versus R-KV’s 17.5% — a 15.4 percentage point gap. On MATH 500 with only 1,024 tokens in the KV cache out of a possible 32,768, TriAttention achieves 68.4% accuracy against Full Attention’s 69.6%. The research team also introduces a Recursive State Query benchmark based on recursive simulation using depth-first search. Recursive tasks stress memory retention because the model must maintain intermediate states across long chains and backtrack to them later — if any intermediate state is evicted, the error propagates through all subsequent return values, corrupting the final result. Under moderate memory pressure up to depth 16, TriAttention performs comparably to Full Attention, while R-KV shows catastrophic accuracy degradation — dropping from approximately 61% at depth 14 to 31% at depth 16. This indicates R-KV incorrectly evicts critical intermediate reasoning states. On throughput, TriAttention achieves 1,405 tokens per second on MATH 500 against Full Attention’s 223 tokens per second, a 6.3× speedup. On AIME25, it achieves 563.5 tokens per second against 222.8, a 2.5× speedup at matched accuracy. Generalization Beyond Mathematical Reasoning The results extend well beyond math benchmarks. On LongBench — a 16-subtask benchmark covering question answering, summarization, few-shot classification, retrieval, counting, and code tasks — TriAttention achieves the highest average score of 48.1 among all compression methods at a 50% KV budget on Qwen3-8B, winning 11 out of 16 subtasks and surpassing the next best baseline, Ada-KV+SnapKV, by 2.5 points. On the RULER retrieval benchmark at a 4K context length, TriAttention achieves 66.1, a 10.5-point gap over SnapKV. These results confirm that the method is not tuned to mathematical reasoning alone — the underlying Q/K concentration phenomenon transfers to general language tasks. Key Takeaways Existing KV cache compression methods have a fundamental blind spot: Methods like SnapKV and R-KV estimate token importance using recent post-RoPE queries, but because RoPE rotates query vectors with position, only a tiny window of queries is usable. This causes important tokens — especially those needed by retrieval heads — to be permanently evicted before they become critical. Pre-RoPE Query and Key vectors cluster around stable, fixed centers across nearly all attention heads: This property, called Q/K concentration, holds regardless of input content, token position, or domain, and is consistent across Qwen3, Qwen2.5, Llama3, and even Multi-head Latent Attention architectures like GLM-4.7-Flash. These stable centers make attention patterns mathematically predictable without observing any live queries: When Q/K vectors are concentrated, the attention score between any query and key reduces to a function that depends only on their positional distance — encoded as a trigonometric series. TriAttention uses this to score every cached key offline using calibration data alone. TriAttention matches Full Attention reasoning accuracy at a fraction of the memory and compute cost: On AIME25 with 32K-token generation, it achieves 2.5× higher throughput or 10.7× KV memory reduction while matching Full Attention accuracy — nearly doubling R-KV’s accuracy at the same memory budget across both AIME24 and AIME25. The method generalizes beyond math and works on consumer hardware. TriAttention outperforms all baselines on LongBench across 16 general NLP subtasks and on the RULER retrieval benchmark, and enables a 32B reasoning model to run on a single 24GB RTX 4090 via OpenClaw — a task that causes out-of-memory errors under Full Attention. Check out the Paper, Repo and Project Page. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us The post Researchers from MIT, NVIDIA, and Zhejiang University Propose TriAttention: A KV Cache Compression Method That Matches Full Attention at 2.5× Higher Throughput appeared first o […]
Long-chain reasoning is one of the most compute-intensive tasks in modern large language models. When a model like DeepSeek-R1 or Qwen3 works through a complex math problem, it can generate tens of thousands of tokens before arriving at an answer. Every one of those tokens must be stored in what is called the KV cache — a memory structure that holds the Key and Value vectors the model needs to attend back to during generation. The longer the reasoning chain, the larger the KV cache grows, and for many deployment scenarios, especially on consumer hardware, this growth eventually exhausts GPU memory entirely. A team of researchers from MIT, NVIDIA, and Zhejiang University proposed a method called TriAttention that directly addresses this problem. On the AIME25 mathematical reasoning benchmark with 32K-token generation, TriAttention matches Full Attention accuracy while achieving 2.5× higher throughput or 10.7× KV memory reduction. Leading baselines achieve only about half the accuracy at the same efficiency level. The Problem with Existing KV Cache Compression To understand why TriAttention is important, it helps to understand the standard approach to KV cache compression. Most existing methods — including SnapKV, H2O, and R-KV — work by estimating which tokens in the KV cache are important and evicting the rest. Importance is typically estimated by looking at attention scores: if a key receives high attention from recent queries, it is considered important and kept. The catch is that these methods operate in what the research team calls post-RoPE space. RoPE, or Rotary Position Embedding, is the positional encoding scheme used by most modern LLMs including Llama, Qwen, and Mistral. RoPE encodes position by rotating the Query and Key vectors in a frequency-dependent way. As a result, a query vector at position 10,000 looks very different from the same semantic query at position 100, because its direction has been rotated by the position encoding. This rotation means that only the most recently generated queries have orientations that are ‘up to date’ for estimating which keys are important right now. Prior work has confirmed this empirically: increasing the observation window for importance estimation does not help — performance peaks at around 25 queries and declines after that. With such a tiny window, some keys that will become important later get permanently evicted. This problem is especially acute for what the research team calls retrieval heads — attention heads whose function is to retrieve specific factual tokens from long contexts. The relevant tokens for a retrieval head can remain dormant for thousands of tokens before suddenly becoming essential to the reasoning chain. Post-RoPE methods, operating over a narrow observation window, see low attention on those tokens during the dormant period and permanently evict them. When the model later needs to recall that information, it is already gone, and the chain of thought breaks. The Pre-RoPE Observation: Q/K Concentration The key insight in TriAttention comes from looking at Query and Key vectors before RoPE rotation is applied — the pre-RoPE space. When the research team visualized Q and K vectors in this space, they found something consistent and striking: across the vast majority of attention heads and across multiple model architectures, both Q and K vectors cluster tightly around fixed, non-zero center points. The research team terms this property Q/K concentration, and measures it using the Mean Resultant Length R — a standard directional statistics measure where R → 1 means tight clustering and R → 0 means dispersion in all directions. On Qwen3-8B, approximately 90% of attention heads exhibit R > 0.95, meaning their pre-RoPE Q/K vectors are nearly perfectly concentrated around their respective centers. Critically, these centers are stable across different token positions and across different input sequences — they are an intrinsic property of the model’s learned weights, not a property of any particular input. The research team further confirm that Q/K concentration is domain-agnostic: measuring Mean Resultant Length across Math, Coding, and Chat domains on Qwen3-8B yields nearly identical values of 0.977–0.980. This stability is what post-RoPE methods cannot exploit. RoPE rotation disperses these concentrated vectors into arc patterns that vary with position. But in pre-RoPE space, the centers remain fixed. From Concentration to a Trigonometric Series The research team then show mathematically that when Q and K vectors are concentrated around their centers, the attention logit — the raw score before softmax that determines how much a query attends to a key — simplifies dramatically. Substituting the Q/K centers into the RoPE attention formula, the logit reduces to a function that depends only on the Q-K distance (the relative positional gap between query and key), expressed as a trigonometric series: logit(Δ)≈∑f‖q‾f‖‖k‾f‖⏟amplitudecos(ωfΔ+ϕ‾f⏟phase)=∑f[afcos(ωfΔ)+bfsin(ωfΔ)] text{logit}(Delta) approx sum_{f} underbrace{|bar{q}_f| |bar{k}_f|}_{text{amplitude}} cos(omega_f Delta + underbrace{bar{phi}_f}_{text{phase}}) = sum_{f} [a_f cos(omega_f Delta) + b_f sin(omega_f Delta)] Here, Δ is the positional distance, ωf are the RoPE rotation frequencies for each frequency band f, and the coefficients af and bf are determined by the Q/K centers. This series produces a characteristic attention-vs-distance curve for each head. Some heads prefer nearby keys (local attention), others prefer very distant keys (attention sinks). The centers, computed offline from calibration data, fully determine which distances are preferred. The research team validated this experimentally across 1,152 attention heads in Qwen3-8B and across Qwen2.5 and Llama3 architectures. The Pearson correlation between the predicted trigonometric curve and the actual attention logits has a mean above 0.5 across all heads, with many heads achieving correlations of 0.6–0.9. The research team further validates this on GLM-4.7-Flash, which uses Multi-head Latent Attention (MLA) rather than standard Grouped-Query Attention — a meaningfully different attention architecture. On MLA, 96.6% of heads exhibit R > 0.95, compared to 84.7% for GQA, confirming that Q/K concentration is not specific to one attention design but is a general property of modern LLMs. How TriAttention Uses This TriAttention is a KV cache compression method that uses these findings to score keys without needing any live query observations. The scoring function has two components: The Trigonometric Series Score (Strig) uses the Q center computed offline and the actual cached key representation to estimate how much attention the key will receive, based on its positional distance from future queries. Because a key may be attended to by queries at many future positions, TriAttention averages this score over a set of future offsets using geometric spacing. Strig(k,Δ)=∑f‖𝔼[qf]‖⋅‖kf‖⋅cos(ωfΔ+ϕf)S_{text{trig}}(k, Delta) = sum_{f} |mathbb{E}[q_f]| cdot |k_f| cdot cos(omega_f Delta + phi_f) The Norm-Based Score (Snorm) handles the minority of attention heads where Q/K concentration is lower. It weights each frequency band by the expected query norm contribution, providing complementary information about token salience beyond distance preference alone. Snorm(0)(k)=∑f𝔼[‖qf‖]⋅‖kf‖S_{text{norm}}^{(0)}(k) = sum_{f} mathbb{E}[|q_f|] cdot |k_f| The two scores are combined using the Mean Resultant Length R as an adaptive weight: when concentration is high, Strig dominates; when concentration is lower, Snorm contributes more. Every 128 generated tokens, TriAttention scores all keys in the cache and retains only the top-B, evicting the rest. Results on Mathematical Reasoning On AIME24 with Qwen3-8B, TriAttention achieves 42.1% accuracy against Full Attention’s 57.1%, while R-KV achieves only 25.4% at the same KV budget of 2,048 tokens. On AIME25, TriAttention achieves 32.9% versus R-KV’s 17.5% — a 15.4 percentage point gap. On MATH 500 with only 1,024 tokens in the KV cache out of a possible 32,768, TriAttention achieves 68.4% accuracy against Full Attention’s 69.6%. The research team also introduces a Recursive State Query benchmark based on recursive simulation using depth-first search. Recursive tasks stress memory retention because the model must maintain intermediate states across long chains and backtrack to them later — if any intermediate state is evicted, the error propagates through all subsequent return values, corrupting the final result. Under moderate memory pressure up to depth 16, TriAttention performs comparably to Full Attention, while R-KV shows catastrophic accuracy degradation — dropping from approximately 61% at depth 14 to 31% at depth 16. This indicates R-KV incorrectly evicts critical intermediate reasoning states. On throughput, TriAttention achieves 1,405 tokens per second on MATH 500 against Full Attention’s 223 tokens per second, a 6.3× speedup. On AIME25, it achieves 563.5 tokens per second against 222.8, a 2.5× speedup at matched accuracy. Generalization Beyond Mathematical Reasoning The results extend well beyond math benchmarks. On LongBench — a 16-subtask benchmark covering question answering, summarization, few-shot classification, retrieval, counting, and code tasks — TriAttention achieves the highest average score of 48.1 among all compression methods at a 50% KV budget on Qwen3-8B, winning 11 out of 16 subtasks and surpassing the next best baseline, Ada-KV+SnapKV, by 2.5 points. On the RULER retrieval benchmark at a 4K context length, TriAttention achieves 66.1, a 10.5-point gap over SnapKV. These results confirm that the method is not tuned to mathematical reasoning alone — the underlying Q/K concentration phenomenon transfers to general language tasks. Key Takeaways Existing KV cache compression methods have a fundamental blind spot: Methods like SnapKV and R-KV estimate token importance using recent post-RoPE queries, but because RoPE rotates query vectors with position, only a tiny window of queries is usable. This causes important tokens — especially those needed by retrieval heads — to be permanently evicted before they become critical. Pre-RoPE Query and Key vectors cluster around stable, fixed centers across nearly all attention heads: This property, called Q/K concentration, holds regardless of input content, token position, or domain, and is consistent across Qwen3, Qwen2.5, Llama3, and even Multi-head Latent Attention architectures like GLM-4.7-Flash. These stable centers make attention patterns mathematically predictable without observing any live queries: When Q/K vectors are concentrated, the attention score between any query and key reduces to a function that depends only on their positional distance — encoded as a trigonometric series. TriAttention uses this to score every cached key offline using calibration data alone. TriAttention matches Full Attention reasoning accuracy at a fraction of the memory and compute cost: On AIME25 with 32K-token generation, it achieves 2.5× higher throughput or 10.7× KV memory reduction while matching Full Attention accuracy — nearly doubling R-KV’s accuracy at the same memory budget across both AIME24 and AIME25. The method generalizes beyond math and works on consumer hardware. TriAttention outperforms all baselines on LongBench across 16 general NLP subtasks and on the RULER retrieval benchmark, and enables a 32B reasoning model to run on a single 24GB RTX 4090 via OpenClaw — a task that causes out-of-memory errors under Full Attention. Check out the Paper, Repo and Project Page. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us The post Researchers from MIT, NVIDIA, and Zhejiang University Propose TriAttention: A KV Cache Compression Method That Matches Full Attention at 2.5× Higher Throughput appeared first o […] -
admin wrote a new post 16 hours, 58 minutes ago
How to Build a Secure Local-First Agent Runtime with OpenClaw Gateway, Skills, and Controlled Tool ExecutionIn this tutorial, we build and operate […]
-
admin wrote a new post 19 hours, 54 minutes ago
HealthcareExplore how clinicians use ChatGPT to support diagnosis, documentation, and patient care with secure, HIPAA-compliant AI tools.
-
admin wrote a new post 22 hours, 50 minutes ago
Responsible and safe use of AILearn how to use AI responsibly with best practices for safety, accuracy, and transparency when using tools like ChatGPT.
-
admin wrote a new post 1 day, 4 hours ago
Understanding BERTopic: From Raw Text to Interpretable Topics Topic modeling uncovers hidden themes in large document collections. Traditional […]
-
admin wrote a new post 1 day, 4 hours ago
How Knowledge Distillation Compresses Ensemble Intelligence into a Single Deployable AI Model
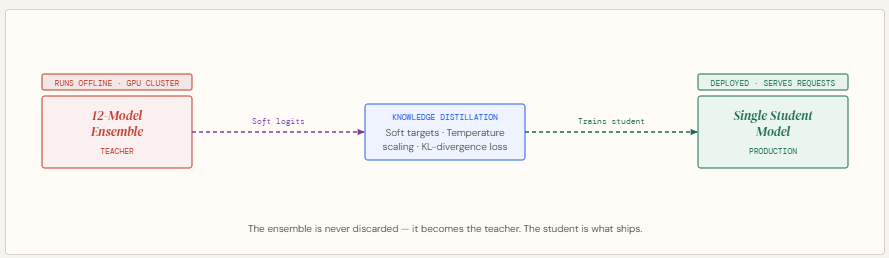 Complex prediction problems often lead to ensembles […]
Complex prediction problems often lead to ensembles […] -
admin wrote a new post 1 day, 13 hours ago
Using custom GPTsLearn how to build and use custom GPTs to automate workflows, maintain consistent outputs, and create purpose-built AI assistants.
-
admin wrote a new post 1 day, 16 hours ago
Research with ChatGPTLearn how to research with ChatGPT using search and deep research to find up-to-date information, analyze sources, and generate structured insights.
-
admin wrote a new post 1 day, 16 hours ago
From Karpathy’s LLM Wiki to Graphify: AI Memory Layers are Here Most AI workflows follow the same loop: you upload files, ask a question, get an […]
-
admin wrote a new post 1 day, 16 hours ago
-
admin wrote a new post 1 day, 16 hours ago
A Coding Guide to Markerless 3D Human Kinematics with Pose2Sim, RTMPose, and OpenSim
 In this tutorial, we build and run a complete Pose2Sim pipeline […]
In this tutorial, we build and run a complete Pose2Sim pipeline […] -
admin wrote a new post 1 day, 16 hours ago
New Manychat Features You’ll Actually Want To Use: PDFs in DMs, Inbox Updates, and MoreThere are product updates, and then there are product updates that make you want to sit up, crack your knuckles, and start doing slightly unwell things…
-
admin wrote a new post 1 day, 16 hours ago
The Influencer Marketing Trends Changing How Brands and Creators CollaborateInstagram marketing is moving fast. What are the latest tactics and how can you apply them to your marketing efforts? Learn the top four trends in this guide.
-
admin wrote a new post 1 day, 16 hours ago
Best AI Chatbot Platforms for E-commerce in 2026In 2026, the competitive landscape of e-commerce demands more than just a compelling product; […]
-
admin wrote a new post 1 day, 16 hours ago
Best AI Chatbot Platforms for E-commerce in 2026In 2026, the competitive landscape of e-commerce demands more than just a compelling product; it […]
-
admin wrote a new post 1 day, 16 hours ago
What’s in a name? Moderna’s “vaccine” vs. “therapy” dilemmaIs it the Department of Defense or the Department of War? The Gulf of Mexico or the Gulf of […]
-
admin wrote a new post 1 day, 16 hours ago
The Download: an exclusive Jeff VanderMeer story and AI models too scary to release
 This is today’s edition of The Download, our weekday n […]
This is today’s edition of The Download, our weekday n […] - Load More
admin
Last active: Active 4 months ago
SHARE:
Comments: 0
Likes: 0
Submitted: 1305
Friends: 0
User Rating: Be the first one!
Adsterra
🔥 Top Offers (Limited Time)
